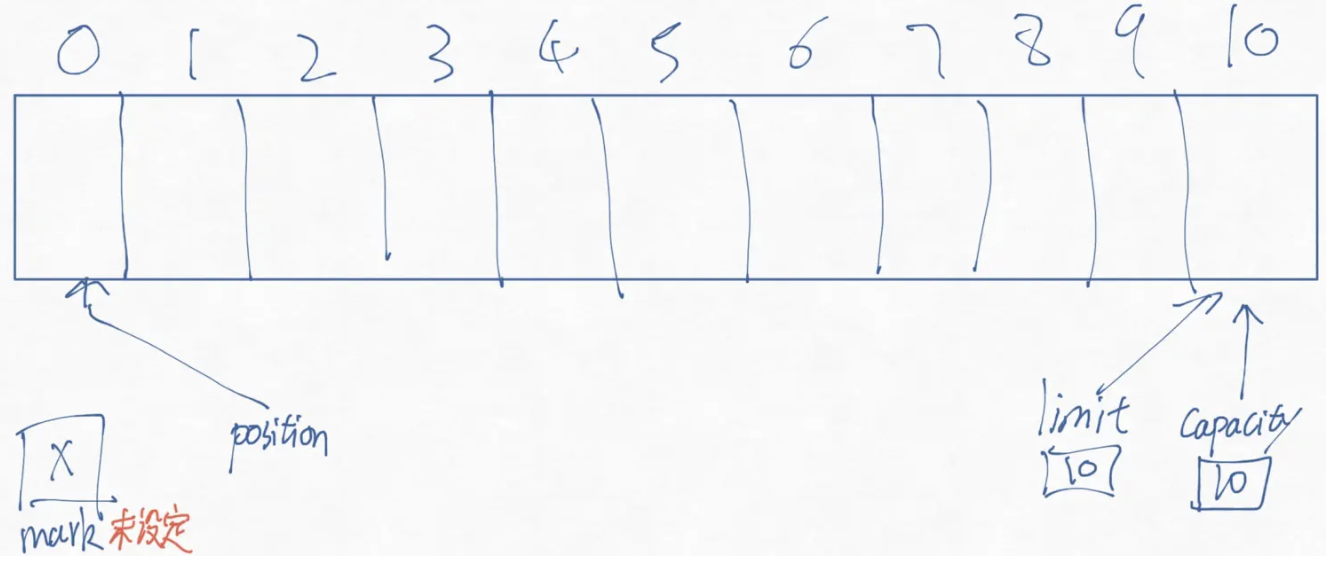
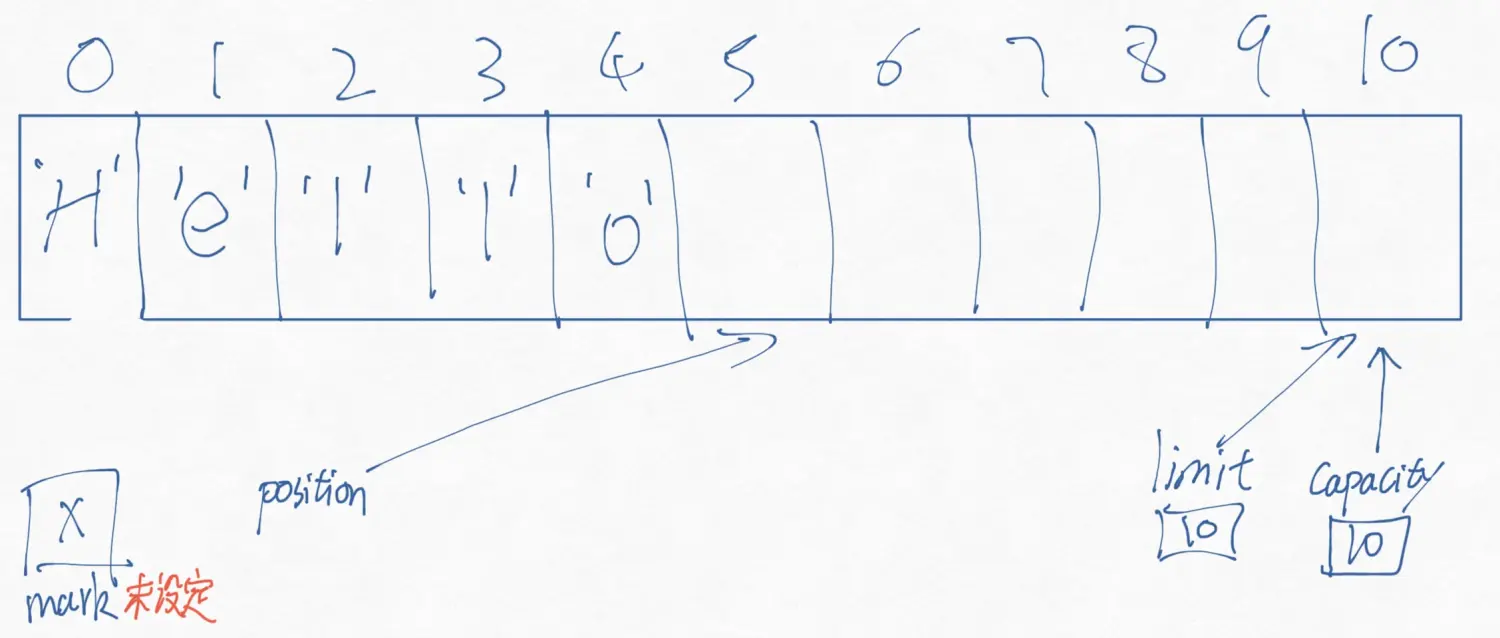
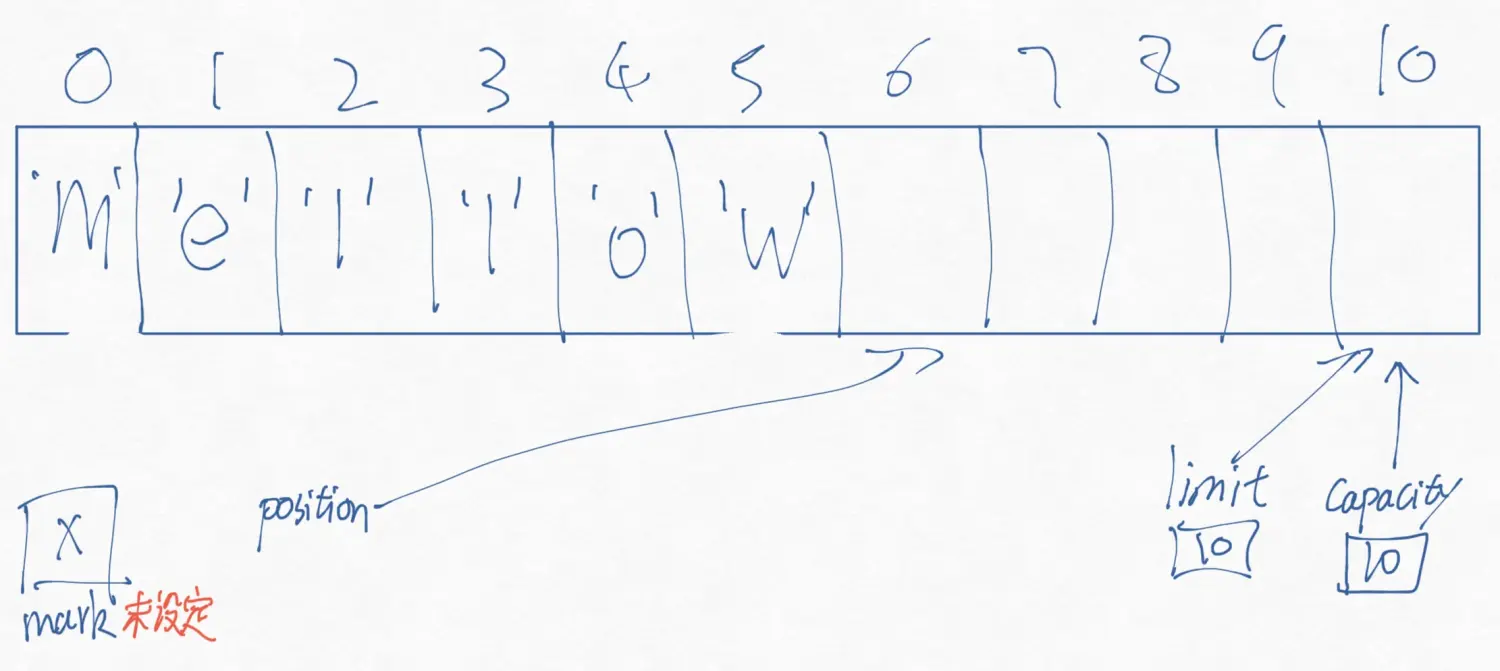
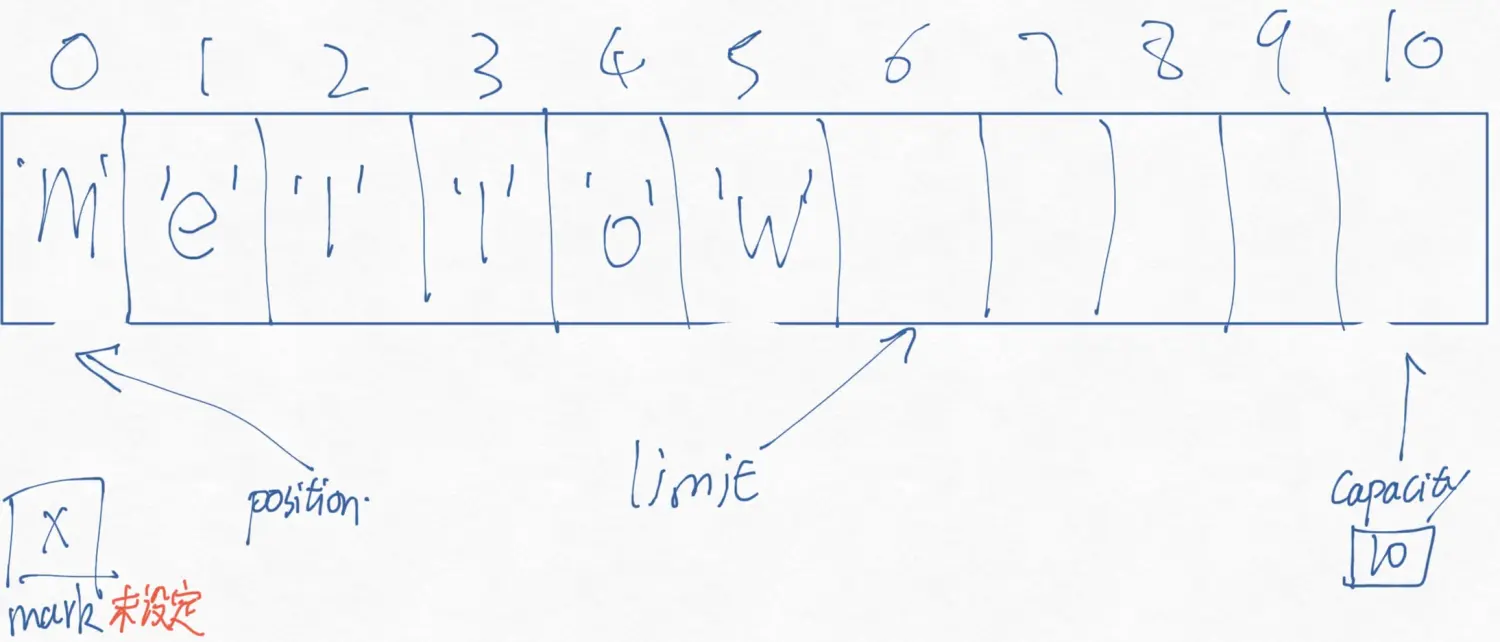
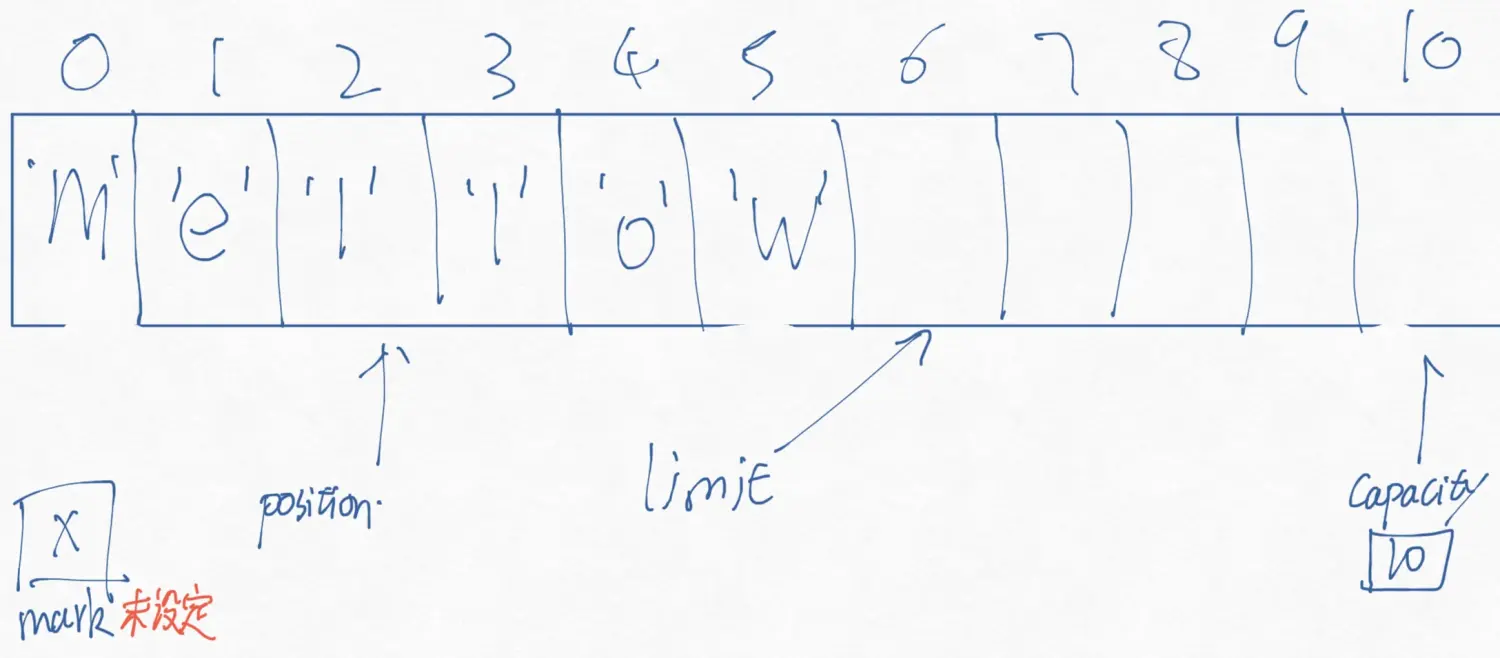
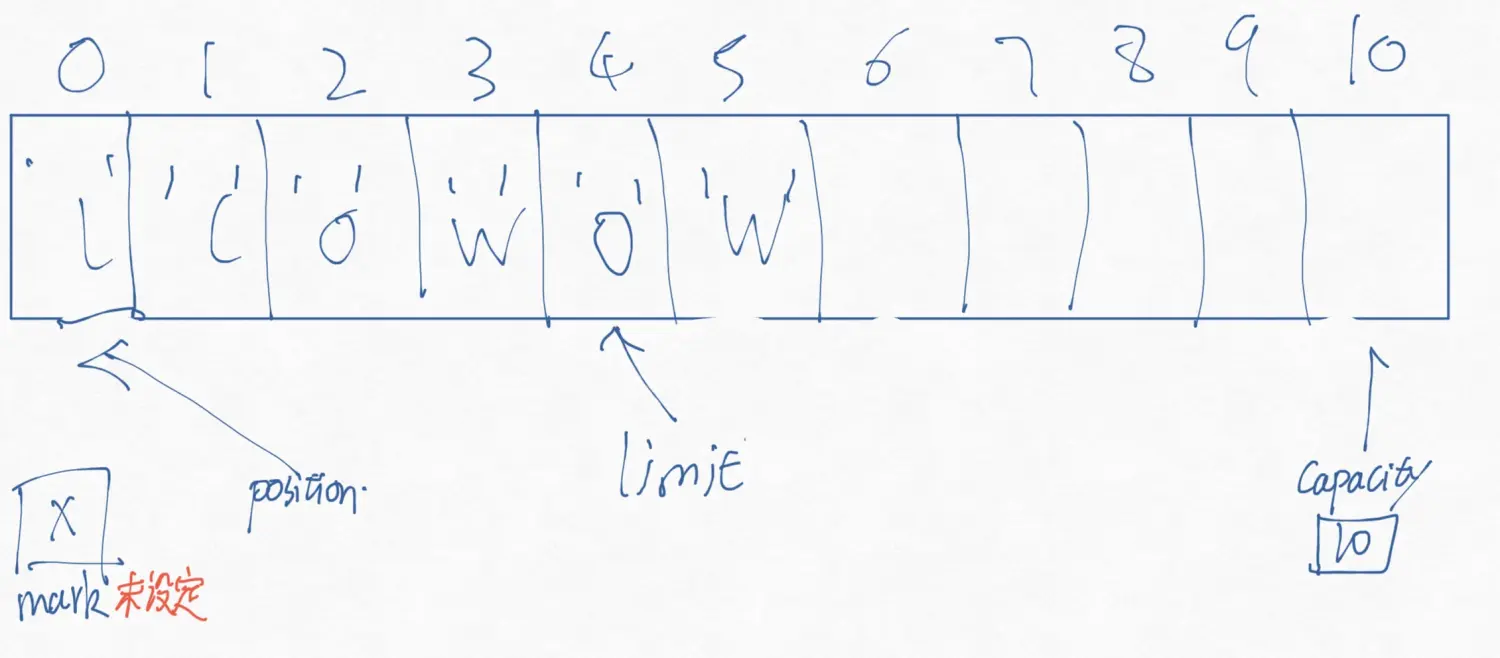
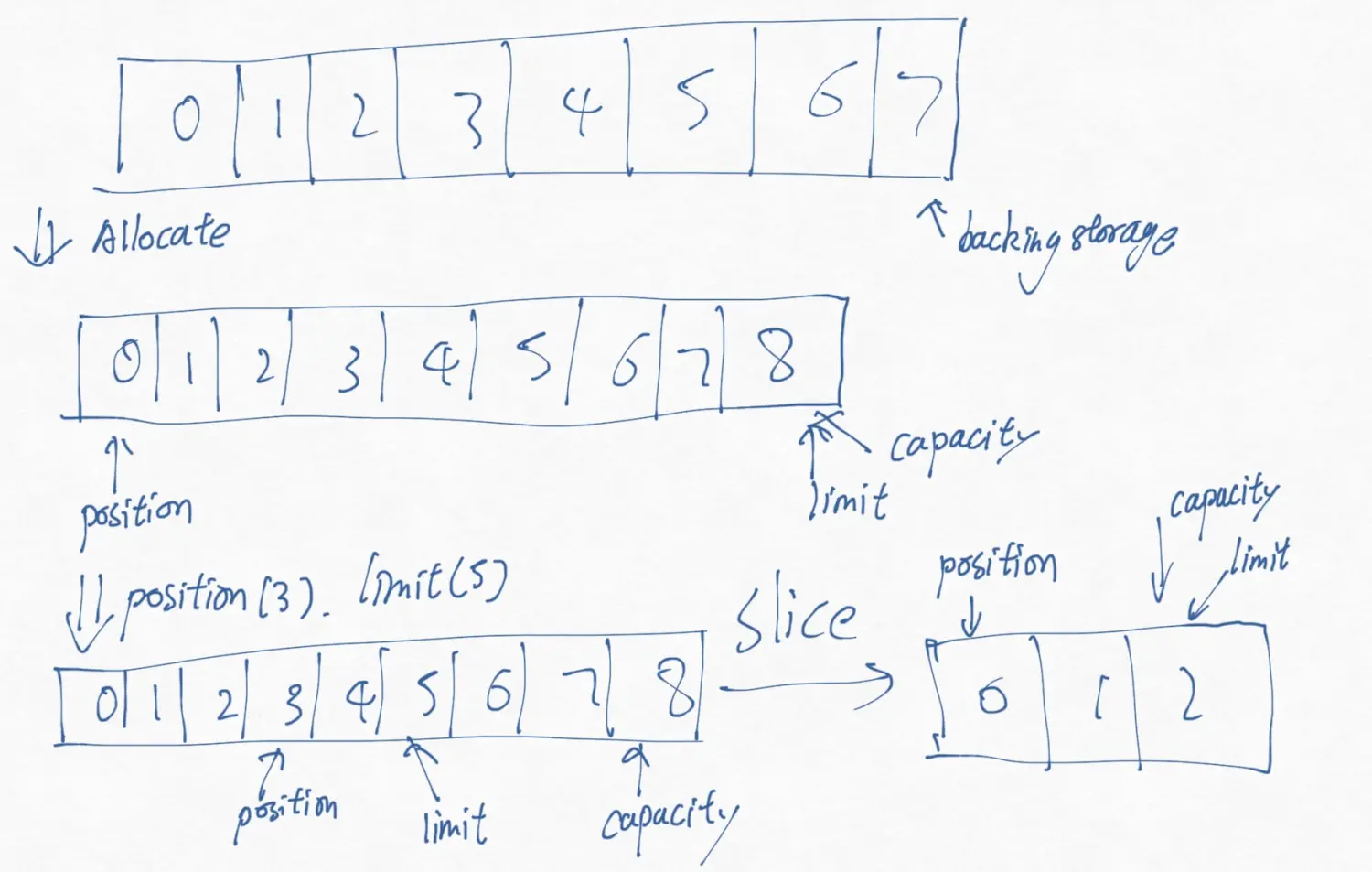
public abstract class Buffer{ public final int capacity() public final int position() public final Buffer position (int newPosition) public final int limit () public final Buffer limit(int newLimit) public final Buffer mark() public final Buffer reset() public final Buffer clear() public final Buffer flip() public final Buffer rewind() public final int remaining() public final boolean hasRemaining(); public abstract boolean isReadOnly(); }
public class BufferFillDrain { //原代码作者 Ron Hitchens ([email protected]) private static int index = 0;
private static String[] strings = { "Hello, this is ZhangJian", "He likes Eminem", "Put the dick in the dust", "And? Fuck the world?", "Lyrics are great", "But what I like more", "is the spirit" };
public abstract class CharBuffer extends Buffer implements CharSequence,Comparable { //这只是方法的一部分 public CharBuffer get (char[] dst) public CharBuffer get(char[] dst, int offset, int length)
public final CharBuffer put (char[] src) public CharBuffer put(char[] src, int offset, int length) public CharBuffer put(char[] src) public final CharBuffer put(String src) public CharBuffer put(String src, int start, int end)
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable { public static CharBuffer allocate (int capacity) public static CharBuffer wrap(char[] array) public static CharBuffer wrap(char[] array, int offset, int length)
public final boolean hasArray() public final char[] array() public final int arrayOffset() }
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable { public abstract CharBuffer duplicate(); public abstract CharBuffer asReadOnlyBuffer(); public abstract CharBuffer slice(); }
public abstract class ByteBuffer extends Buffer implements Comparable { public static ByteBuffer allocate(int capacity) public static ByteBuffer allocateDirect(int capacity) public abstract boolean isDirect(); }
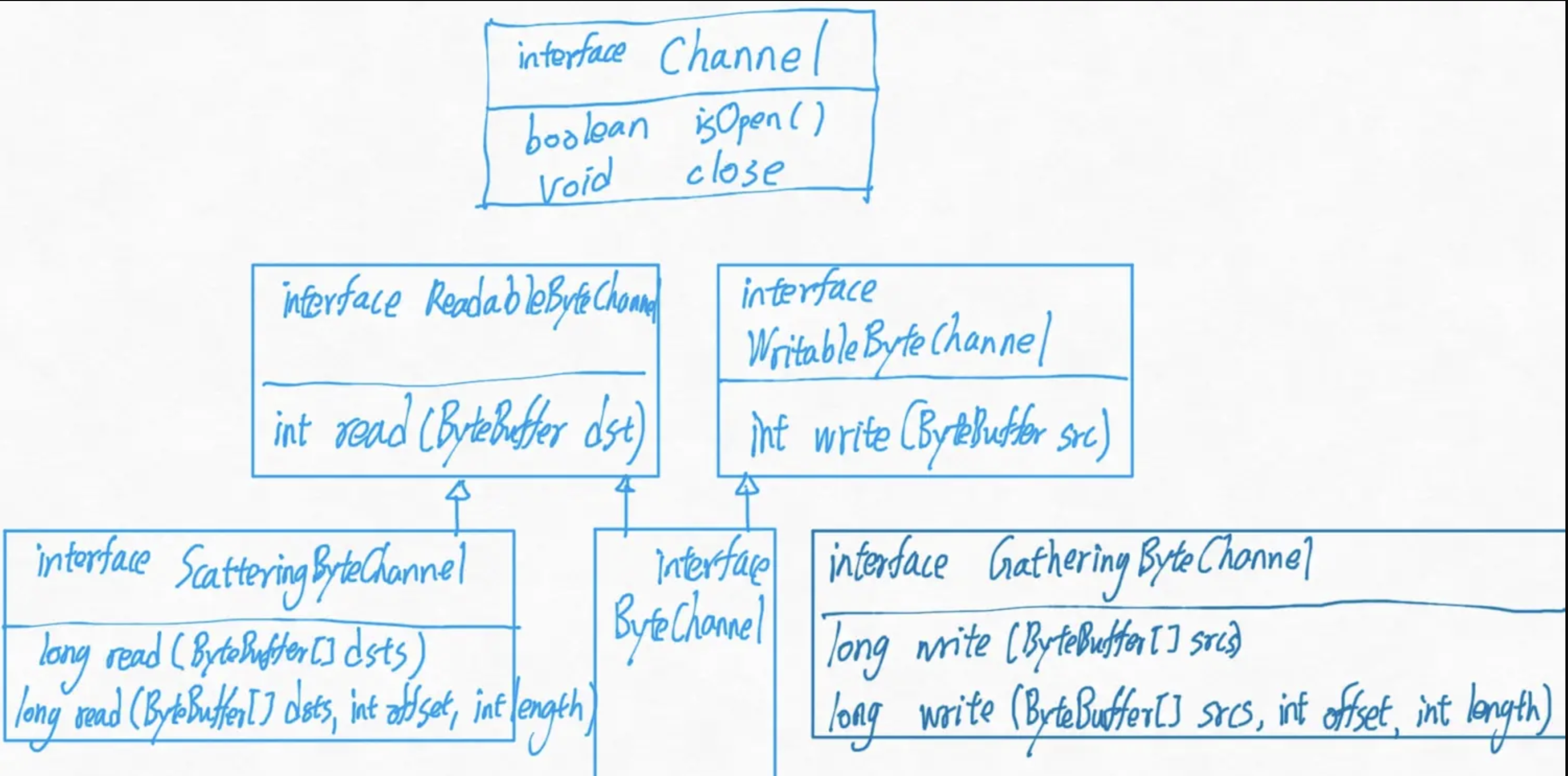
public interface ReadableByteChannel extends Channel { public int read (ByteBuffer dst) throws IOException; } public interface WritableByteChannel extends Channel { public int write(ByteBuffer src) throws IOException; } public interface ByteChannel extends ReadableByteChannel, WritableByteChannel { }
public interface ReadableByteChannel extends Channel { public int read (ByteBuffer dst) throws IOException; } public interface WritableByteChannel extends Channel { public int write(ByteBuffer src) throws IOException; } public interface ByteChannel extends ReadableByteChannel, WritableByteChannel { }
public interface ScatteringByteChannel extends ReadableByteChannel { public long read(ByteBuffer[] dsts) throws IOException; public long read(ByteBuffer[] dots,int offset, int length) throws IOException; }
public interface GatheringByteChannel extends WritableByteChannel { public long write(ByteBuffer[] srcs) throws IOException; public long write(ByteBuffer[] srcs, int offset, int length) throws IOException; }
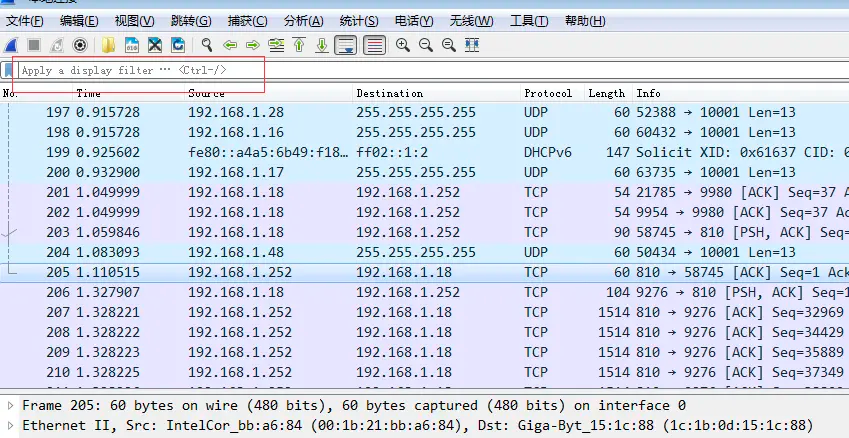
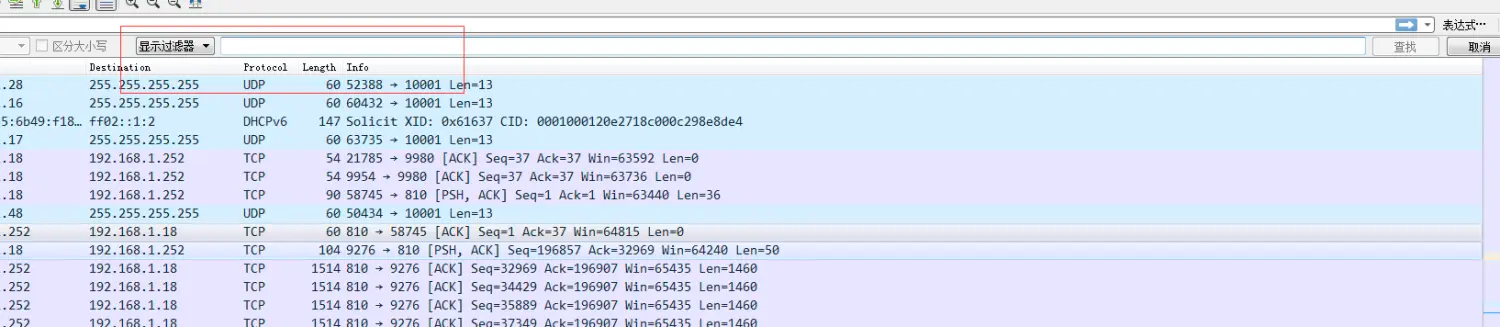
看看下面的代码段
1 2 3 4
ByteBuffer header = ByteBuffer.allocateDirect(10); ByteBuffer body = ByteBuffer.allocateDirect(80); ByteBuffer[] buffers = {header, body}; int bytesRead = channel.read(buffers);
如果返回值bytesRead为48,那么head中拥有最先的10个数据,body中有38个。
相似的,我们可以组装数据在不同的buffer中,然后发送聚合
1 2 3 4 5
body.clear(); body.put("FOO".getBytes()).flip(); header.clear(); header.putShort(TYPE_FILE).putLong(body.limit()).flip(); long bytesWritten = channel.write(buffers);
public class FileLock implements AutoClosable{ public FileChannel channel() public long position() public long size() public boolean isShared() public boolean overlaps(long position, long size) public boolean isValid() public void release() public String toString() }
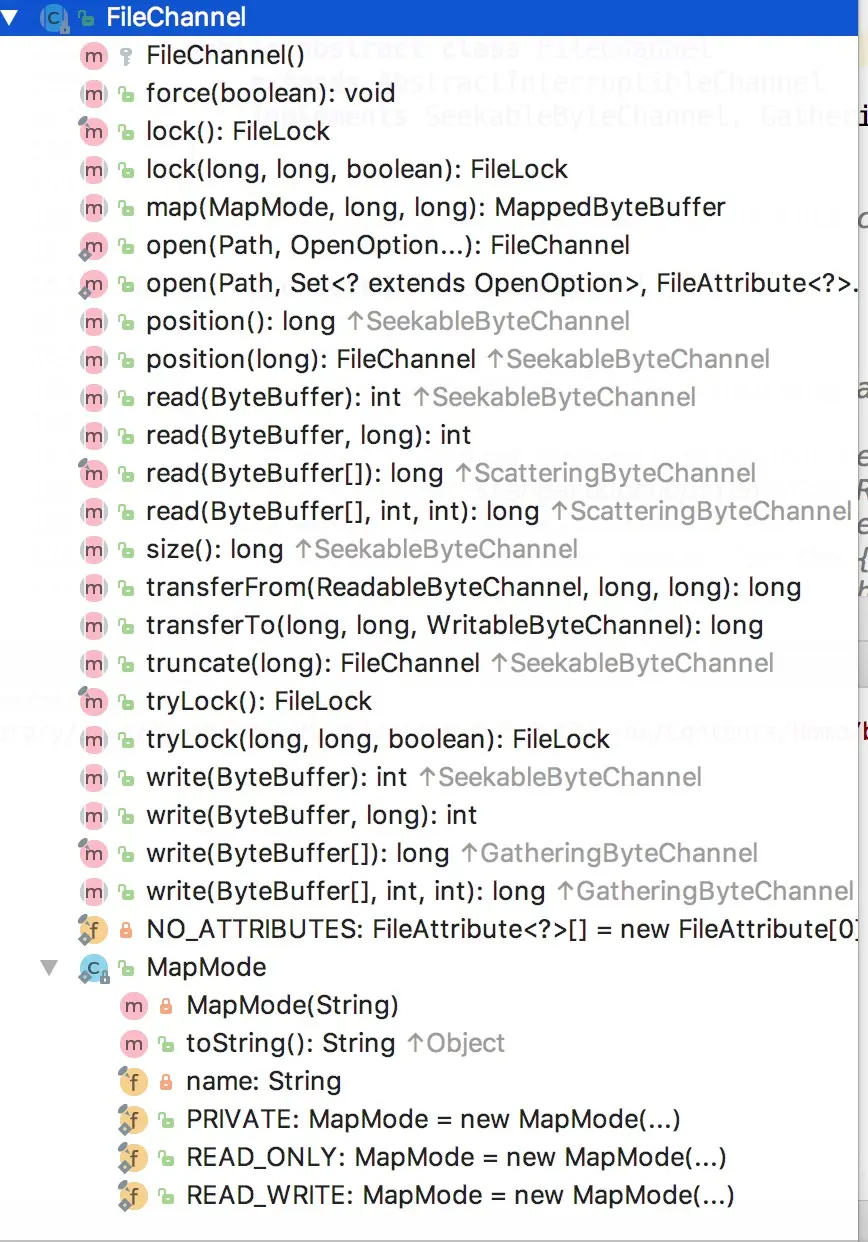
public abstract class FileChannel extends AbstractChannel implements ByteChannel, GatheringByteChannel, ScatteringByteChannel { public final FileLock lock() public abstract FileLock lock (long position, long size, boolean shared)
public final FileLock tryLock() public abstract FileLock tryLock(long position, long size, boolean shared) }
private static final int SIZEOF_INT = 4; private static final int INDEX_START = 0; private static final int INDEX_COUNT = 10; private static final int INDEX_SIZE = INDEX_COUNT * SIZEOF_INT;
private ByteBuffer buffer = ByteBuffer.allocate(INDEX_SIZE); private IntBuffer indexBuffer = buffer.asIntBuffer(); private Random rand = new Random();
public abstract int read() throws IOException public int read(byte[] data) throws IOException public int read(byte[] data, int offset, int length) throws IOException public long skip(long n) throws IOException public int available() throws IOException public void close() throws IOException public synchronized void mark(int readLimit) public synchronized void reset() throws IOException public boolean markSupported()
try{ int[] data = new int[10]; for(int i=0;i<data.length;i++) { int datum = System.in.read(); if (datum == -1) break; data[i] = datum; } } catch (IOException e ) { System.err.println("Couldn't read from System.in!"); }
public class StreamPrinter { InputStream theInput; public static void main(String[] args) { StreamPrinter sr = new StreamPrinter(System.in); sr.print(); }
public StreamPrinter(InputStream in) { theInput = in; } public void print() { try{ while(true) { int datum = theInput.read(); if (datum == -1) break; System.out.println(datum); } } catch (IOException e) { System.err.println("couldn't read from system in") } } }
public int read() throws IOException public int read(byte[] data) throws IOException public int read(byte[] data, int offset, int length) throws IOException public native long skip(long n) throws IOException public native int available() throws IOException public native void close() throws IOException
public FileInputStream(String fileName) throws IOException public FileInputStream(File file) throws FileNotFoundException public FileInputStream(FileDescriptor fdObj)
FileInputStream fis = new FileInputStream("README.TXT"); int n; while ((n=fis.available())>0) { byte[] b = new byte[n]; int result = fis.read(b); if( result == -1) break; String s = new String(b); System.out.print(s); }
public class FileOutputStream extends OutputStream
类中实现了OutputStream的所有常用方法
1 2 3 4
public native void write(int b) throws IOException public void write(byte[] data) throws IOException public void write(byte[] data, int offset, int length) throws IOException public native void close() throws IOException
public FileOutputStream(String filename) throws IOException public FileOutputStream(File file) throws IOException public FileOutputStream(FileDescriptor fd)
public class Main { public static void main(String[] args) throws IOException { URL url = new URL("http://www.huawei.com"); URLConnection uc = url.openConnection(); uc.connect(); InputStream in = uc.getInputStream(); //...after operation //close the stream in.close(); } }
public Socket (String host, int port) throws UnknownHostException, IOException public Socket(InteAddress address, int port) throws IOException public Socket(String host, int port, InetAddress localAddr, int localPort) throws IOException public Socket(InetAddress address, int port, InetAddress localAddr, int localPort) throws IOException
public ServerSocket (int port) throws IOException public ServerSocket (int port, int backlog) throws IOException public ServerSocket (int port, int backlog, InetAddress bindAddr) throws IOException
通常情况下你指定你想要监听的端口
1 2 3 4 5
try { ServerSocket ss = new ServerSocket(99); } catch (IOException e) { e.printStackTrace(); }