灵活部署要求
常见的微服务开发下,可能会对微服务的日志打印有一些要求.常见的一种模式是,将日志文件挂载在主机路径中,然后在主机上启动filebeat收集日志.
以我的一个demo工程rabbitmq-adapt为例:
1
2
| 容器内打印路径: /opt/sh/logs/file.log
容器外挂载路径: /opt/log/rabbitmq/file.log
|
但是这样子,如果我们需要在一个虚拟机上跑两个rabbitmq-adapt的时候,日志路径会重复,这种情况下,不仅我们在虚拟机很难定位问题,而且filebeat也很难给日志标记上不同实例的标签.
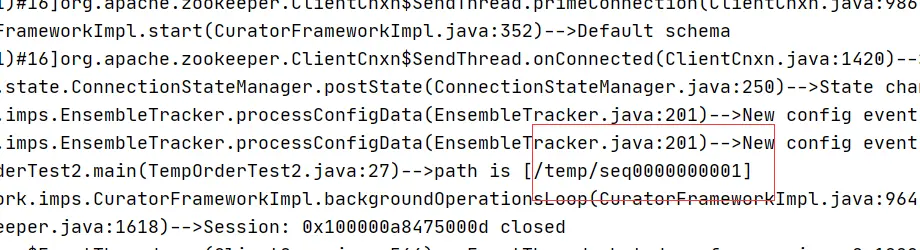
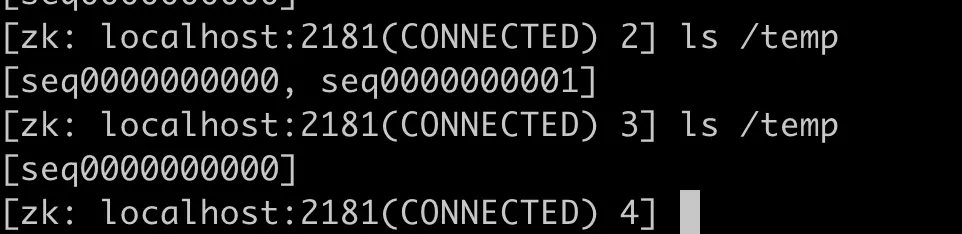
所以首先,我们得把日志路径按pod实例的方式隔离,选择k8s中HOSTNAME环境变量作为文件路径前缀是一个不错的选择
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| akka@AkkadeMacBook-Pro ~ % kubectl exec -it rabbitmq-58c5f4ff6b-zthg4 bash
[root@rabbitmq-58c5f4ff6b-zthg4 /]# env
LANG=en_US.UTF-8
HOSTNAME=rabbitmq-58c5f4ff6b-zthg4
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
KUBERNETES_PORT=tcp://10.96.0.1:443
POD_NAME=rabbitmq-58c5f4ff6b-zthg4
PWD=/
HOME=/root
NODE_NAME=minikube
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT_443_TCP_PORT=443
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
TERM=xterm
SHLVL=1
KUBERNETES_SERVICE_PORT=443
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
POD_IP=172.17.0.2
KUBERNETES_SERVICE_HOST=10.96.0.1
LESSOPEN=||/usr/bin/lesspipe.sh %s
_=/usr/bin/env
|
k8s subPathExpr方案: 查阅资料,官方推荐的是这个方案
这个时候,你的映射关系是 /opt/sh/logs <==> /opt/log/rabbitmq/${POD_NAME}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| apiVersion: apps/v1
kind: Deployment
metadata:
name: rabbitmq
labels:
app: rabbitmq
spec:
replicas: 2
selector:
matchLabels:
app: rabbitmq
template:
metadata:
labels:
app: rabbitmq
spec:
containers:
- name: rabbitmq
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
image: hezhangjian/rabbitmq-adapt:0.0.1
readinessProbe:
httpGet:
path: /readiness
port: 8083
initialDelaySeconds: 3
periodSeconds: 3
volumeMounts:
- mountPath: /opt/sh/log
name: rabbitmq-log
subPathExpr: $(POD_NAME)
resources:
limits:
memory: 4G
cpu: 1000m
requests:
memory: 500M
cpu: 250m
securityContext:
privileged: true
volumes:
- name: rabbitmq-log
hostPath:
path: /opt/log/rabbitmq
type: DirectoryOrCreate
|
可以达到如下的效果:
1
| minikube/ rabbitmq-6df8f7565c-kh2h6/ rabbitmq-6df8f7565c-ss92l/
|
log4j2环境变量隔离方案:适用于在你的k8s版本还不够的情况下
这个时候,你的文件映射关系还是 /opt/sh/logs <==> /opt/log/rabbitmq
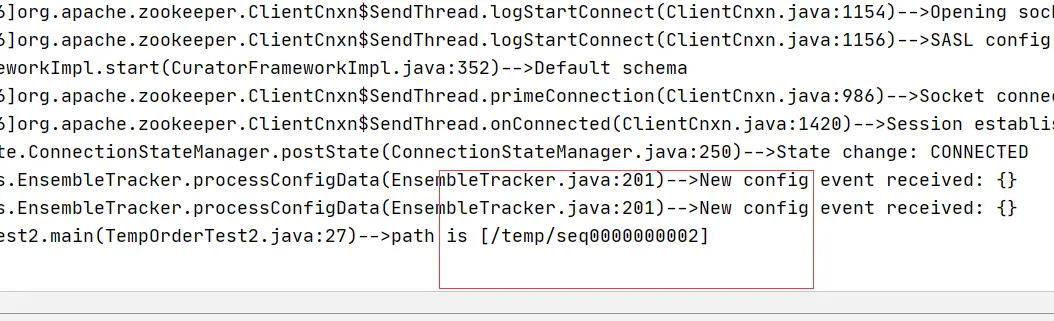
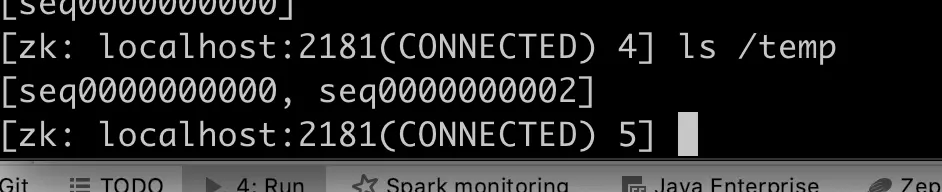
但是真正在打印日志的时候,把日志都打印到/opt/sh/logs/${POD_NAME}下,这样子也可以在一台vm上跑多个实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <?xml version="1.0" encoding="UTF-8" ?>
<Configuration status="warn" monitorInterval="10">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{yyyy-MM-dd,HH:mm:ss,SSSXXX}(%r):%4p%X[%t#%T]%l-->%m%n"/>
</Console>
<File name="FILE" fileName="${env:HOSTNAME}/file.log">
<PatternLayout pattern="%d{yyyy-MM-dd,HH:mm:ss,SSSXXX}(%r):%4p%X[%t#%T]%l-->%m%n"/>
</File>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="Console"/>
<AppenderRef ref="FILE"/>
</Root>
</Loggers>
</Configuration>
|
我们解决了两个容器在一个vm上打印日志的问题,紧接着,我们要分析filebeat的能力,filebeat能否区分这两个路径,把这两个路径打上不同的标签
运行并配置好filebeat,配置文件如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/sh/collect/log/es/*/*.log
tags: ["es"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
reload.period: 10s
setup.template.settings:
index.number_of_shards: 1
fields:
fields_under_root: true
setup.kibana:
output.elasticsearch:
hosts: ["localhost:9200"]
processors:
- add_host_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata:
kube_config: /opt/sh/collect/log/config
logging.level: debug
|
,查询收集上来的数据
1
2
| curl 127.0.0.1:9200/filebeat-7.5.1-2020.01.23-000001/_search?pretty
收集上来的数据存在hostname字段,能区分代表单个实例的信息.
|
使用ES processor添加实例id信息
1
2
3
4
5
6
7
8
9
10
11
12
| curl -X PUT "localhost:9200/_ingest/pipeline/attach_instance?pretty" -H 'Content-Type: application/json' -d'
{
"processors": [
{
"grok": {
"field": "log.file.path",
"patterns": ["/opt/sh/collect/log/es/%{WORD:instanceId}/es.log"]
}
}
]
}
'
|
然后修改filebeat配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/sh/collect/log/es/*/*.log
tags: ["es"]
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
reload.period: 10s
setup.template.settings:
index.number_of_shards: 1
fields:
fields_under_root: true
setup.kibana:
output.elasticsearch:
hosts: ["localhost:9200"]
pipeline: attach_instance
processors:
- add_host_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata:
kube_config: /opt/sh/collect/log/config
logging.level: debug
|
查询结果就会出现在instanceId字段
总结
三种方案均可以方便地实现同一vm上部署两个容器. 方案一只需要修改tosca模板,但要1.14版本才支持.方案二需要修改少量代码.
但前两种均不适合配置了hostnetwork,即独占主机的网络,原因,主机网络独占之后,两个容器的hostname都相同,实际中,已经独占网络的容器,还需要部署在一个节点的需求,应该比较少.
如果有,可以使用在es处处理文件路径,加上instanceId字段