错误码国际化总结
错误信息无模板变量
假设我们的错误信息返回如下
1 | HTTP/1.1 200 OK |
无模板变量的错误信息国际化,可以直接在前端对整体字符串根据错误码进行静态国际化。
1 | // catch the error code first |
错误信息包含模板变量
假设我们的错误信息返回如下
1 | HTTP/1.1 200 OK |
包含模板变量的错误信息国际化,可以在前端通过正则表达式提取,并代入到中文字符串模板中实现。如示例代码
1 | // catch the error code first |
假设我们的错误信息返回如下
1 | HTTP/1.1 200 OK |
无模板变量的错误信息国际化,可以直接在前端对整体字符串根据错误码进行静态国际化。
1 | // catch the error code first |
假设我们的错误信息返回如下
1 | HTTP/1.1 200 OK |
包含模板变量的错误信息国际化,可以在前端通过正则表达式提取,并代入到中文字符串模板中实现。如示例代码
1 | // catch the error code first |
从Spring的新版本开始,推荐使用构造函数的注入方式,通过构造函数注入有很多优点,诸如不变性等等。同时在构造函数上,也不需要添加@Autowire
注解就可以完成注入
1 | // Before |
但是,这种注入方式会导致变动代码的时候,需要同时修改field以及构造函数,在项目早期发展时期,这种变动显得有一些枯燥,再加上已经不需要@Autowire
注解。这时,我们可以用Lombok的@RequiredArgsConstructor来简化这个流程。
Lombok的@RequiredArgsConstructor会包含这些参数:
对于那些被标记为 @NonNull
的字段,还会生成一个显式的空检查(不过在Spring框架里这个没什么作用)。通过应用@RequiredArgsConstructor
,代码可以简化为如下模样,同时添加新的字段也不需要修改多行。
1 |
|
对于maven项目来说,模块的划分和pom(Project)文件可谓是至关重要,但往往在商业代码中,maven模块和pom文件并不得到大家的重视,最终导致模块杂乱、pom文件复杂难度,进而导致团队维护成本高。随意地exclude,随意地指定版本号,只会将项目带入依赖管理的地狱。本文讲述maven项目模块布局以及pom文件书写原则。
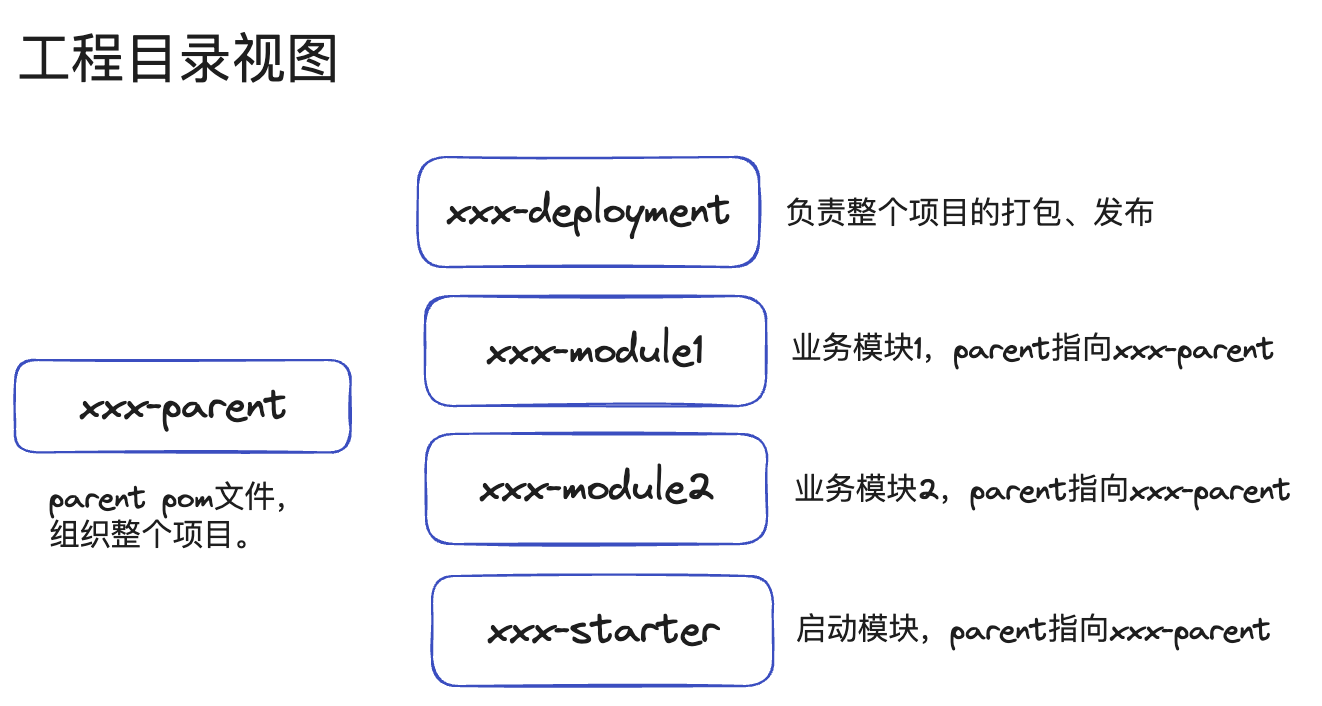
常见的一个需要打包发布、发布到maven仓库、并提供本项目bom的maven模块划分,以项目名xxx为例,当然,实际的项目可能会更加复杂,拥有common、util模块等。
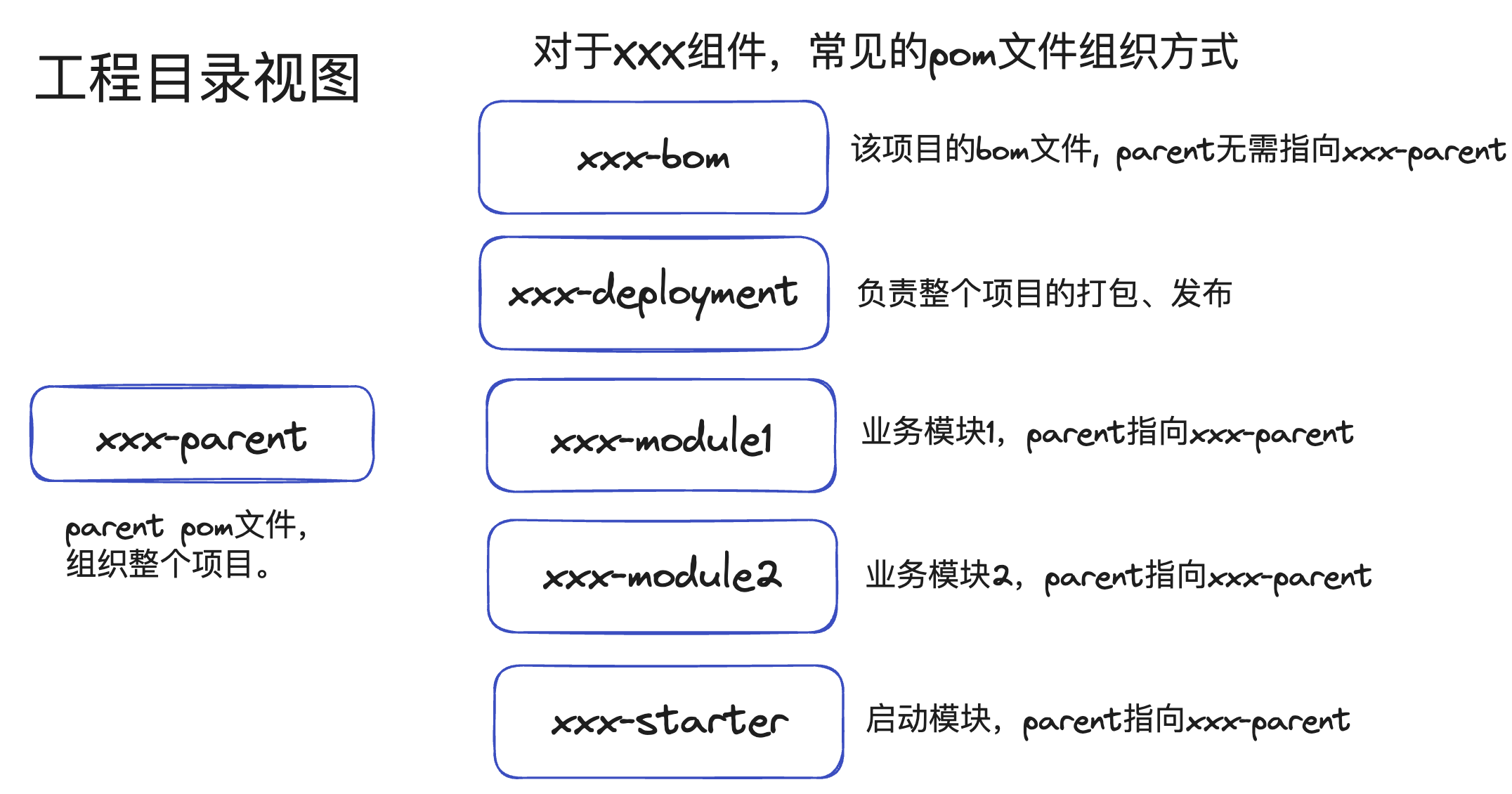
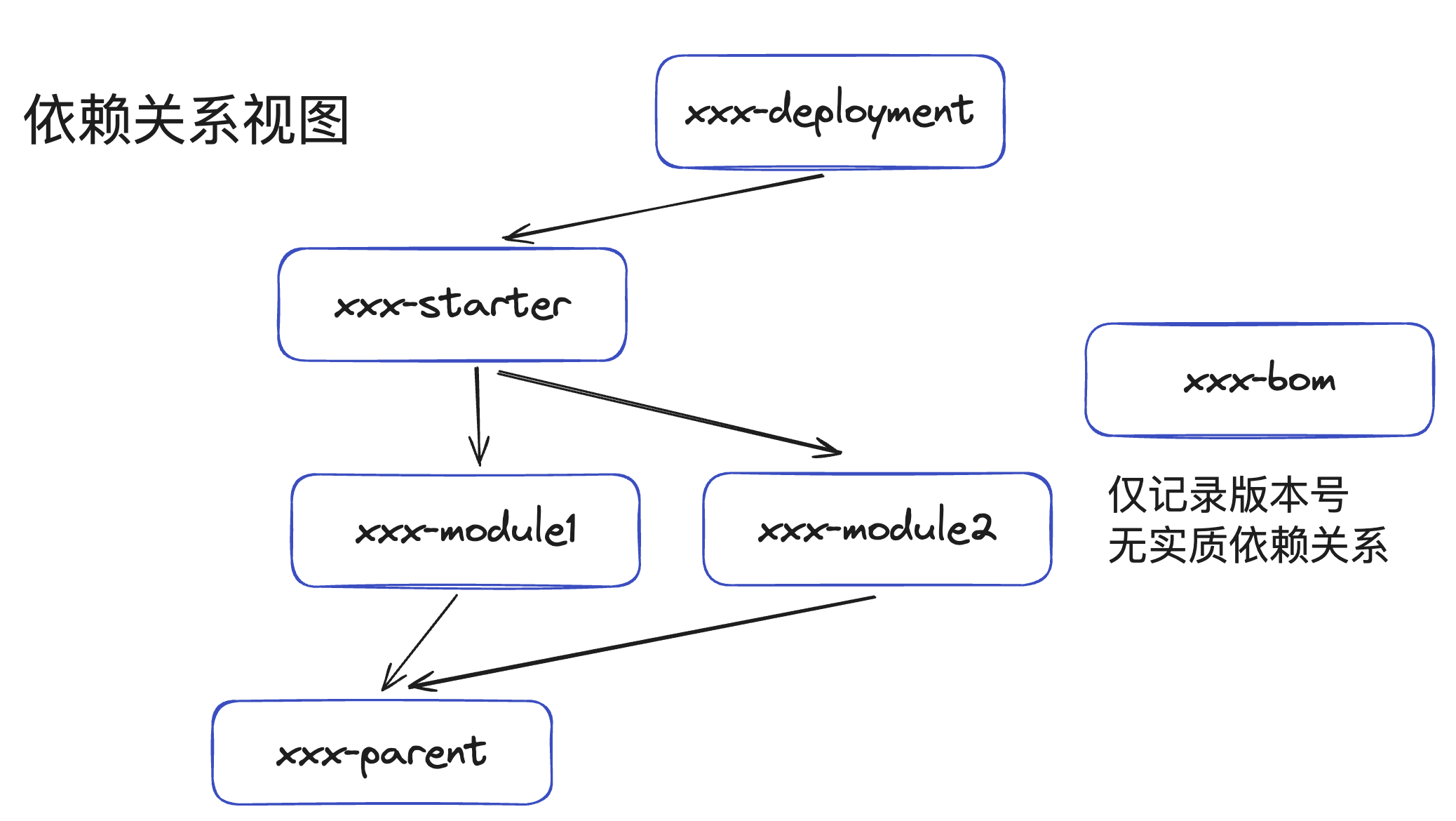
xxx-parent用来组织整个工程,常见的可以放一些诸如java版本、checkstyle、spotbugs等配置,xxx-parent也可以考虑以上层依赖/组织发布的parent作为parentxxx-parent会有很多的依赖、插件配置,xxx-bom仅给其他项目提供版本号,没必要引入过多的依赖。很多商业微服务,根本不涉及会将代码的一部分发布成library给其他人使用,那么可以进行简化,将bom去除
java基于jar包而不是源码的依赖方式是jar包版本冲突罪恶的源头,像Netty这样基于4.1,一直维护了100多个小版本的library何其之少。这导致了java应用程序依赖的jar包,需要一个微妙的关系才能搭配运行,比如springboot3.x才能对应hibernate 6.x版本等。对于一个springboot项目,我们没有必要也没有意义去定义hibernate的版本号,只需要将Spring的依赖指定为parent就可以了。
对于大部分项目来说,子模块使用的依赖版本号都是一致的。尽量将版本号都通过parent或通过<properties> 统一管理引用起来,比如
1 | <properties> |
对于一些bom文件较为简单的项目,比如netty、jackson等,引入没有问题。但引入多个大项目的dependency management,比如同时引入公司内的parent、springboot某个dependency parent、再比如同时引入两个springboot衍生项目作为dependency management,可能会导致依赖版本传递关系复杂,难以维护。
举个例子:
对于library依赖,不应该把log4j2作为自己的compile级别依赖,只能作为runtime和test级别的依赖。
大部分情况下,无需进行exclue、特殊指定某个组件的版本号,仅当版本冲突,或紧急漏洞修复。每一个exclude、指定版本号都应该有合理的原因。尽量不在某一个子模块里单独exclude、指定版本号。合理的exclude如
1 | <!-- use log4j2 instead of logback --> |
pom文件就和代码一样,优美的pom应该整洁、避免重复、在项目中拥有统一的风格。
某个节点下有大量的元素时,优先按照含义区分先后顺序,比如compile依赖在先,test依赖在后;比如按依赖顺序pulsar-api在先,pulsar-client在后,其次可以按照字母顺序排列。会大大提升整个pom文件的可读性。
依赖管理,可以按照compile、runtime、test,并按照依赖的重要程序排序。比如在opengemini-client-reactor中,将本项目的模块放在上面,三方依赖放在下面
1 | <dependencies> |
properties里面,可以按全局、依赖、插件分别归类,并在小类中按字母名称排序。示例如下:
1 | <properties> |
maven从3.5.0版本开始,支持revision。允许其他模块引用父pom里面的版本号。IDEA对这个特性的支持还不是特别好,比如父pom里面定义
1 | <groupId>com.shoothzj</groupId> |
主要的好处有两条:
如果您的项目不涉及这两条,那么大可不必使用这个特性
对于一个资源实体来说,在解决方案里,常见的操作场景有:
可以将实体命名如下: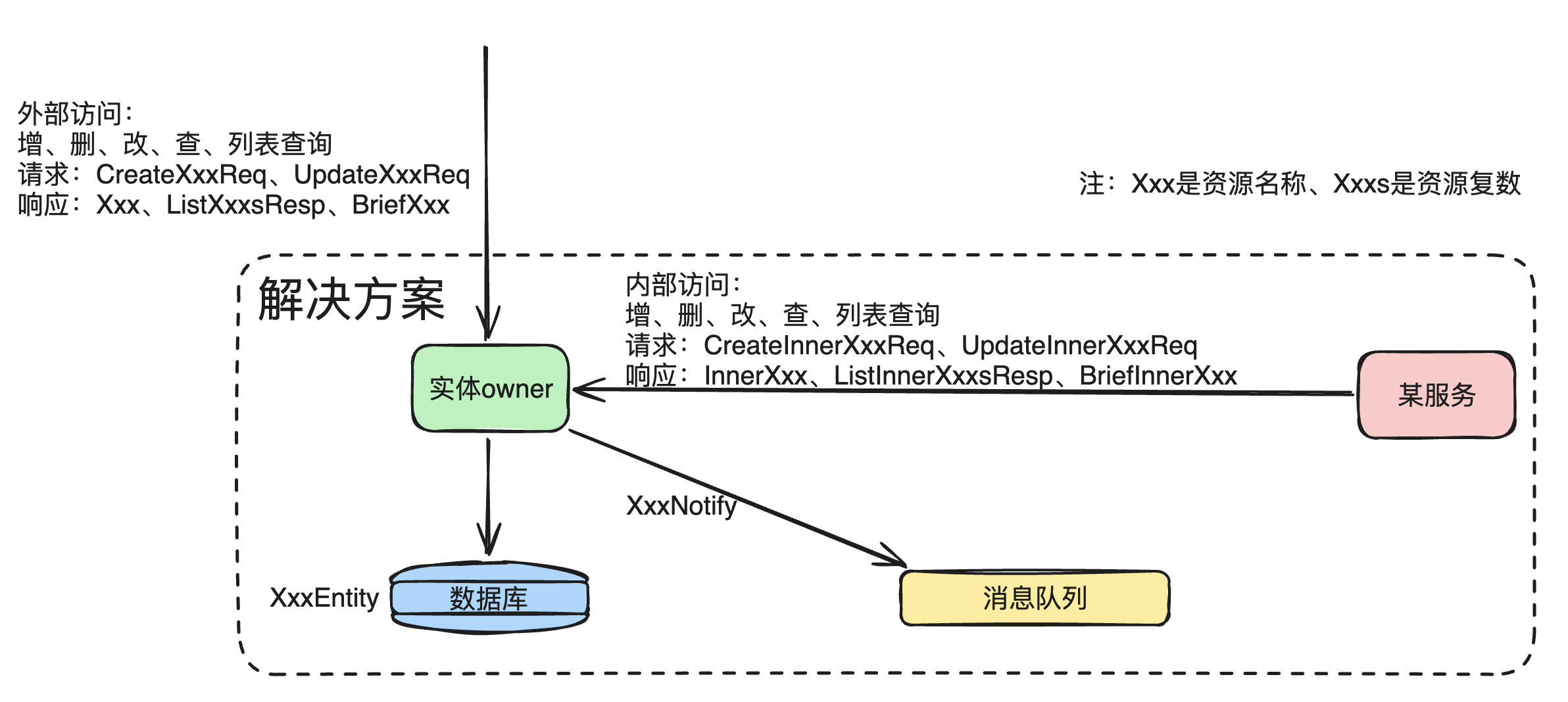
实体类详细说明:
出于复杂性的考虑,可以将XxxNotify类跟InnerXxx进行简化合并,转化为:
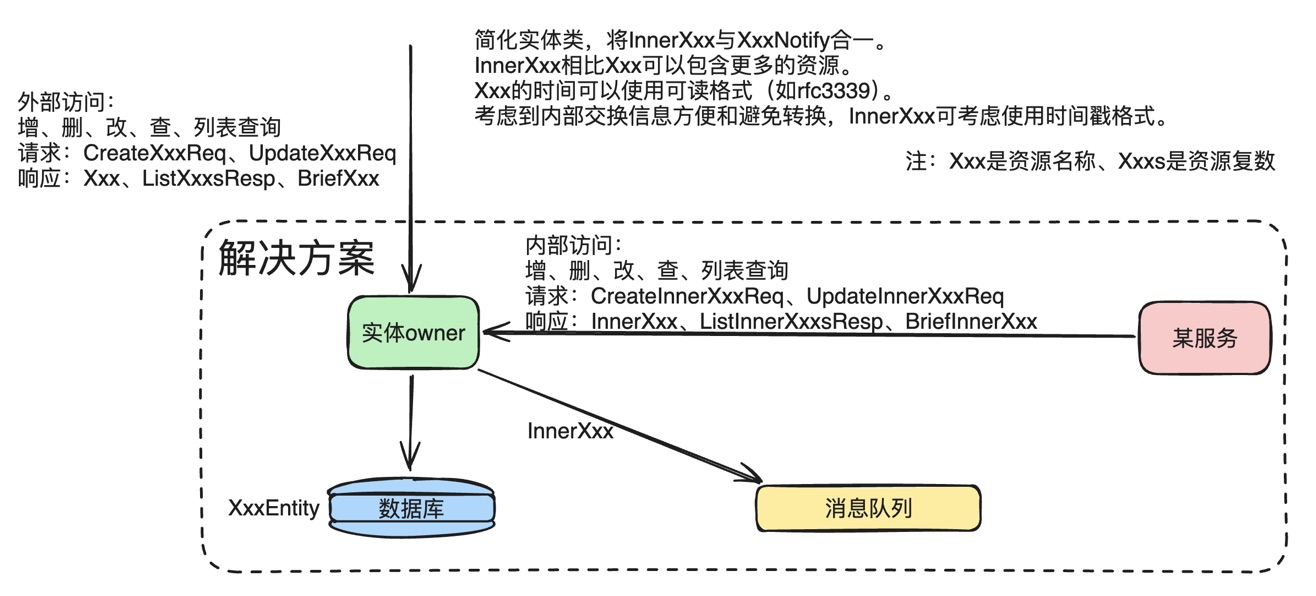
swagger/openapi里,operationId可使用如下
| 操作 | operationId |
|---|---|
| 创建资源 | CreateXxx |
| 删除资源 | DeleteXxx |
| 更新资源 | UpdateXxx |
| 查询单个资源 | ShowXxx |
| 查询资源列表 | ListXxx |
| 内部创建资源 | CreateInnerXxx |
| 内部删除资源 | DeleteInnerXxx |
| 内部更新资源 | UpdateInnerXxx |
| 内部查询单个资源 | ShowInnerXxx |
| 内部查询资源列表 | ListInnerXxx |
在现代应用编码中,从数据库里面find出来,进行一些业务逻辑操作,最后再save回去。即:
1 | Person person = personRepo.findById(id); |
但是这样的业务操作,如果一个线程修改年龄,另一个线程修改昵称,最后save回去,可能会导致年龄/昵称某一个的修改被覆盖。
sequenceDiagram
participant A as Thread A
participant B as Thread B
participant DB as Database
A->>DB: find person by id
Note over A: person.setAge(18)
B->>DB: find person by id
Note over B: person.setNickname("NewName")
A->>DB: save person
B->>DB: save person
Note over DB: Potential Overwrite Issue
常见的解决方案有两种
通过分布式锁等方式,保证同一时间只有一个线程能够对数据进行修改。
版本控制是另一种流行的处理并发问题的方法。它通过在每次更新记录时递增版本号来确保数据的一致性。
这在JPA中,可以通过在field上添加@Version注解来实现,但这也就要求①数据库中必须有version字段,②对于查找后更新类操作,必须使用JPA的save方法来进行更新。
当然也可以通过update_time来模拟乐观锁实现,这可能需要你在更新的时候添加update_time的条件,并且,update_time在极端场景下,理论正确性没那么严谨。
在软件开发中,分页没有统一的规范,实现方式也各不相同,有的会返回总页数,有的会返回总条数,有的可以任意翻页。本文对比一下几种常见的分页方式。
总体来说,分页的实现方案分为四种:
sequenceDiagram
participant 前端
participant 后端
前端 ->> 后端: 请求资源集数据
后端 -->> 前端: 返回全部数据
| 前端功能 | 支持情况 |
|---|---|
| 显示总页 | 🙂 |
| 任意页码跳转 | 🙂 |
| 跳转附近数页 | 🙂 |
| 大量数据集 | 😭完全不可用 |
| 实现难度 | 简单 |
sequenceDiagram
participant 前端
participant 后端
前端 ->> 后端: 请求满足条件的资源总数
后端 -->> 前端: 返回满足条件的资源总数
前端 ->> 后端: 请求资源集数据、PageNo
后端 -->> 前端: 部分数据
| 前端功能 | 支持情况 |
|---|---|
| 显示总页 | 🙂 |
| 任意页码跳转 | 🙂 |
| 跳转附近数页 | 🙂 |
| 大量数据集 | 😭海量数据集下性能差 |
| 实现难度 | 相对简单 |
sequenceDiagram
participant 前端
participant 后端
前端 ->> 后端: 请求满足条件的资源总数
后端 -->> 前端: 返回满足条件的资源总数
前端 ->> 后端: 请求资源集数据、cursor、limit
后端 -->> 前端: 部分数据、prevCursor、nextCursor
| 前端功能 | 支持情况 |
|---|---|
| 显示总页 | 🙂 |
| 任意页码跳转 | 😭 |
| 跳转附近数页 | 🙂 |
| 大量数据集 | 🙂 |
| 实现难度 | 相对复杂 |
如果每一次翻页都返回总页数的话,对性能来讲也是不小的开销。
相对动态的数据来说,如果不一直翻到没有数据为止,也不好确定是否到了最后一页。为了解决这个问题,以及跳转附近数页的问题,可以演进为这样的方案。
假定前端最多显示最近6页,每页50条数据,那么前端可以直接尝试预读300条数据,根据返回的数据来做局部的分页。一言以蔽之:读取更多的数据来进行局部分页。
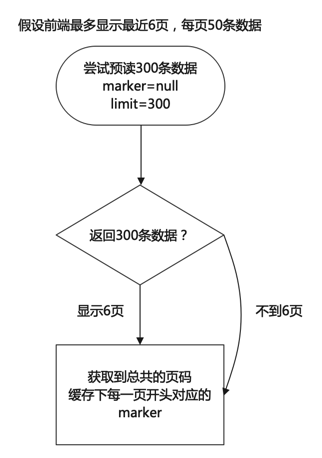
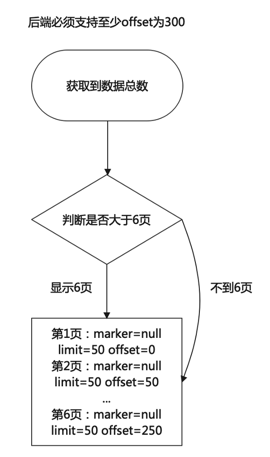
这里可以再简化一下前端的实现,添加offset参数,这样子前端只需要判断当前页前后数据条数是否足够,附近页的跳转可以通过携带offset字段请求得到。
Spring记录数据库操作时间的几种方式
@EnableJpaAuditing注解开启Jpa的审计功能,然后在实体类上使用@CreatedDate和@LastModifiedDate注解即可
1 |
|
Spring R2dbc可以使用@CreatedDate和@LastModifiedDate注解来实现。但是需要在Application上开启@EnableR2dbcAuditing
1 |
|
应用程序修改就比较简单,简单设置一下即可,以PersonPo类为例
1 | PersonPo personPo = new PersonPo(); |
1 | CREATE TABLE person ( |
本文介绍常见的异步网络请求编码手法。尽管像golang这些的语言,支持协程,可以使得Programmer以同步的方式编写代码,大大降低编码者的心智负担。但网络编程中,批量又非常常见,这就导致即使在Golang中,也不得不进行协程的切换来满足批量的诉求,在Golang中往往对外以callback的方式暴露接口。
无论是callback、还是返回future、还是返回Mono/Flux,亦或是从channel中读取,这是不同的异步编程范式,编码的时候,可以从项目整体、团队编码风格、个人喜好来依次考虑。本文将以callback为主,但移植到其他异步编码范式,并不困难。
使用callback模式后,对外的方法签名类似:
go
1 | func (c *Client) Get(ctx context.Context, req *Request, callback func(resp *Response, err error)) error |
java
1 | public interface Client { |
对于网络请求来说,批量可以提高性能。 批量处理是指将多个请求或任务组合在一起,作为单一的工作单元进行处理。批量尽量对用户透明,用户只需要简单地对批量进行配置,而不需要关心批量的实现细节。
常见的批量相关配置
批量可以通过定时任务实现,也可以做一些优化,比如队列中无请求时,暂停定时任务,有请求时,启动定时任务。
整体流程大概如下图所示:
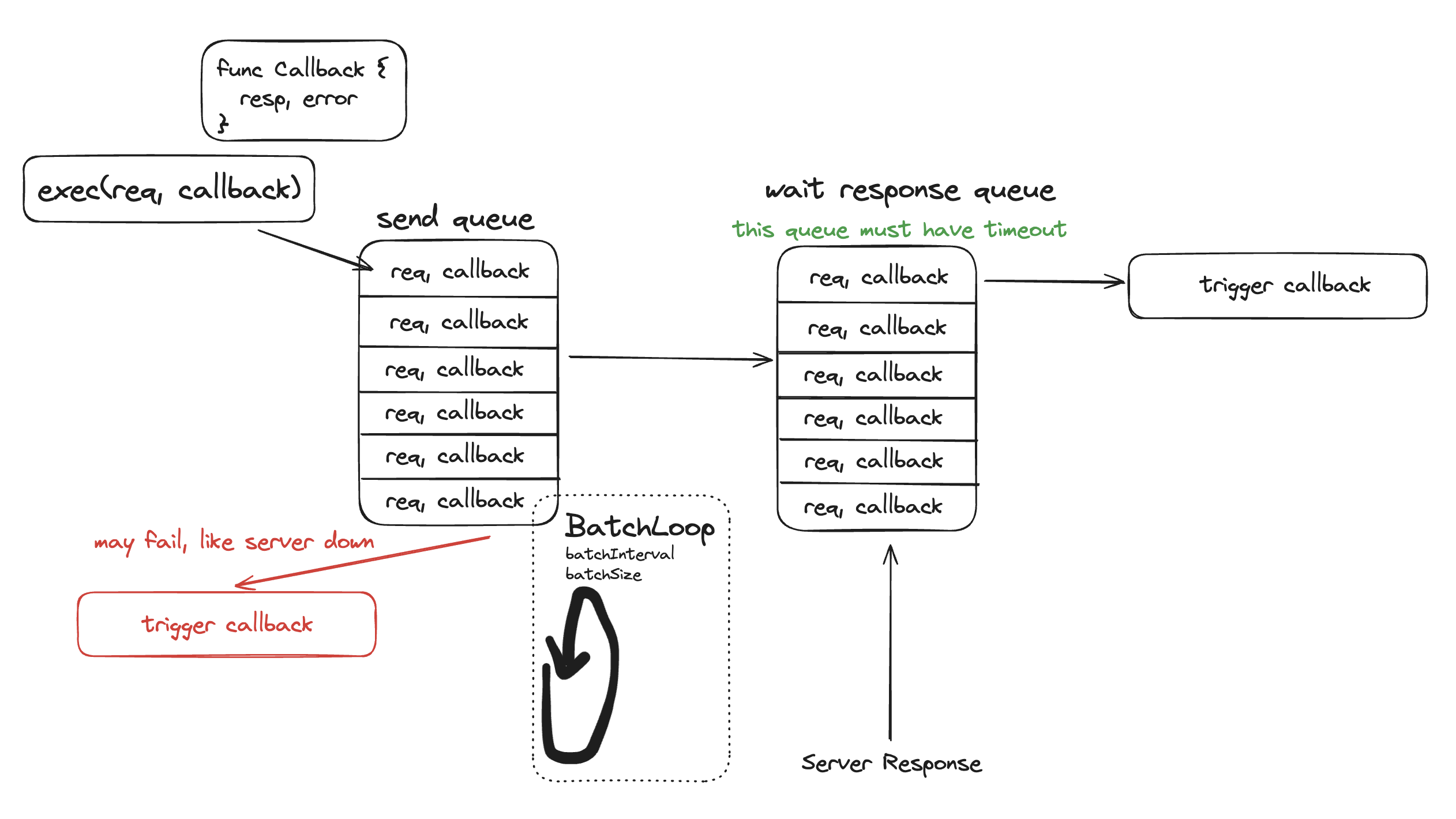
避免网络请求响应过快,导致callback还没注册上,就已经收到响应了。
避免由于丢包等原因,导致请求一直没有响应,而导致队列中的请求越来越多,最终内存溢出。
wait队列中请求一定是依附于client的,一旦client重建,队列也需要重建,并触发callback、future的失败回调。
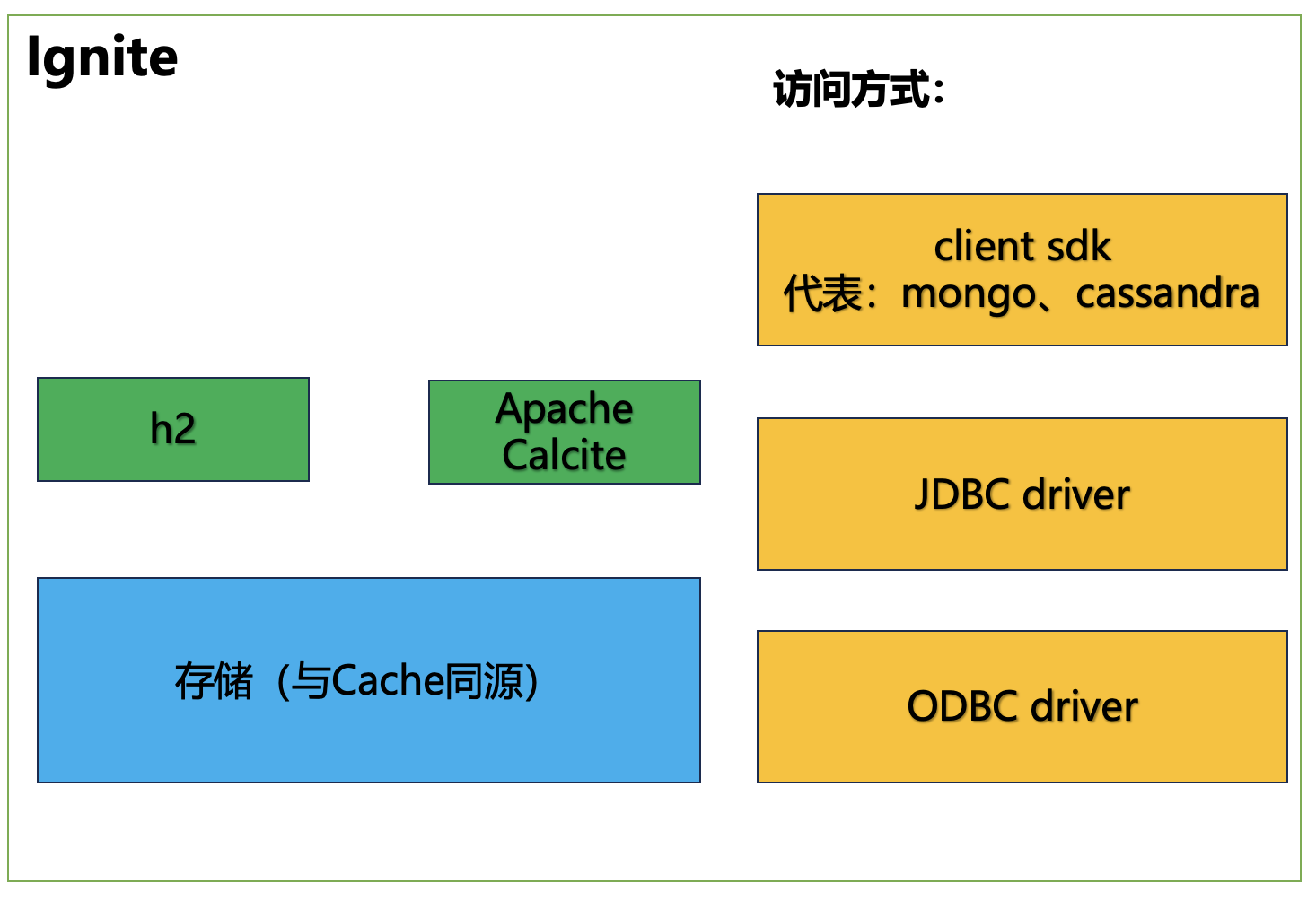
Apache Ignite是一个开源分布式的数据库、缓存和计算平台。它的核心是一个内存数据网格,它可以将内存作为分布式的持久化存储,以提供高性能和可扩展性。它还提供了一个分布式的键值存储、SQL数据库、流式数据处理和复杂的事件处理等功能。
Ignite的核心竞争力包括:
同时,为了便于开发,除了jdbc、odbc、restful方式外,Ignite还官方提供了Java、C++、.Net、Python、Node.js、PHP等语言的客户端,可以方便的与Ignite进行交互。
根据Ignite2的拓扑模型,集群的拓扑版本会在创建表/删除表的时候发生变化,该变化版本号递增,且仅会保留最近$IgniteDiscoveryHistorySize条记录,程序某处会写死读取版本为0的数据,读取不到时,ignite集群会重启。默认值为500。
社区issue: https://github.com/apache/ignite/issues/10894
笔者暂时没有时间来修复这个issue,可以通过将IGNITE_DISCOVERY_HISTORY_SIZE设置地比较大,来规避这个问题。
Ignite2客户端的连接超时、执行sql超时默认都是0,没有精心研究过配置的用户在异常场景下,应用程序可能会hang住。从易用性的角度来说,网络通信的任何操作,默认都应该有超时时间。
Ignite通过预先计算出所有需要重连的时间点来实现重连,如果想配置成永远的重连,会因为时间点的计算导致内存溢出。从易用性的角度来说,应该支持永远的重连。
当client执行sql的时候,碰到如下异常的时候,无法自愈。可以通过执行SQL对client进行定期检查并重建。
1 | Caused by: org.apache.ignite.internal.client.thin.ClientServerError: Ignite failed to process request [47]: 50000: Can not perform the operation because the cluster is inactive. Note, that the cluster is considered inactive by default if Ignite Persistent Store is used to let all the nodes join the cluster. To activate the cluster call Ignite.cluster.state(ClusterState.ACTIVE) |
Ignite客户端在连接时,如果对应的Server端没有启动,会导致SocketChannel泄露,已由笔者提交代码修复:https://github.com/apache/ignite/pull/11016/files
1 | name: commit lint |
1 | name: line lint |
1 | name: go ci Lint |
1 | name: go mod check |
1 | name: go unit test |
1 | name: java checkstyle |
1 | name: java spotbugs |
1 | name: java unit tests |
1 | name: npm build test |
1 | name: prettier |