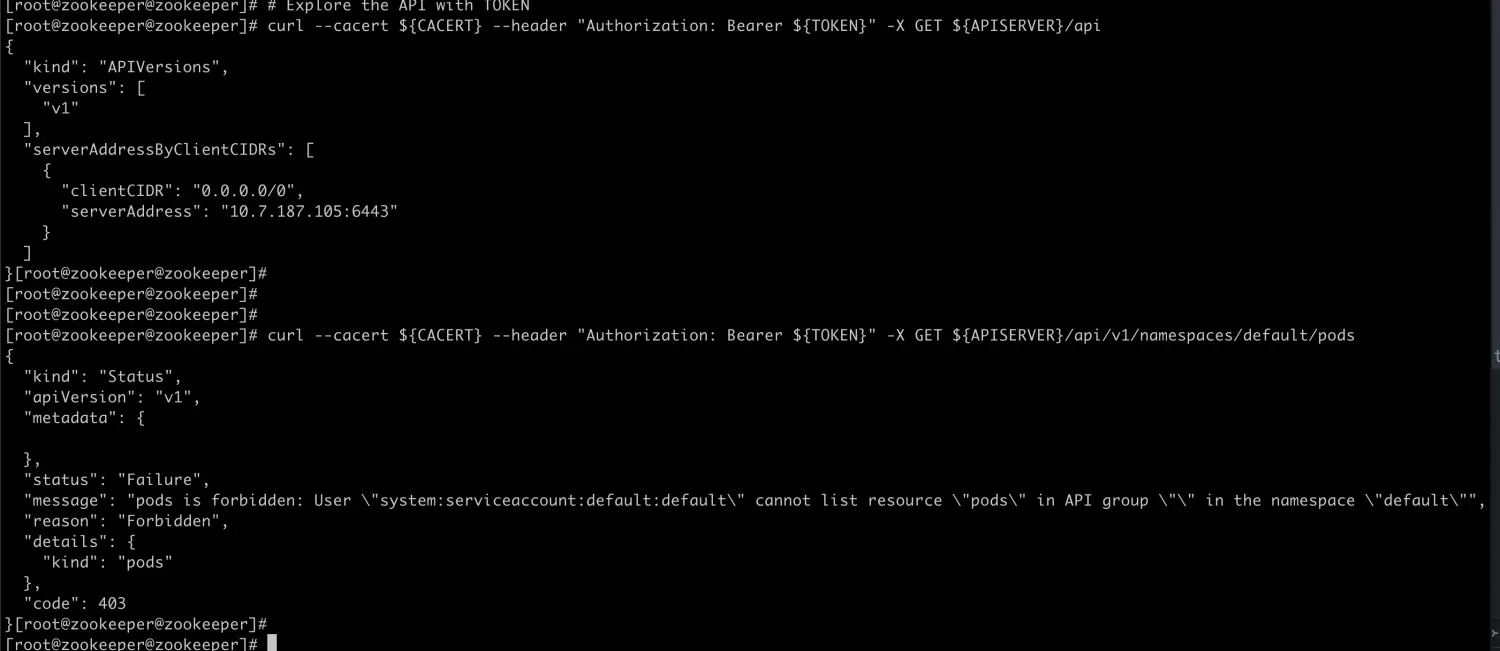
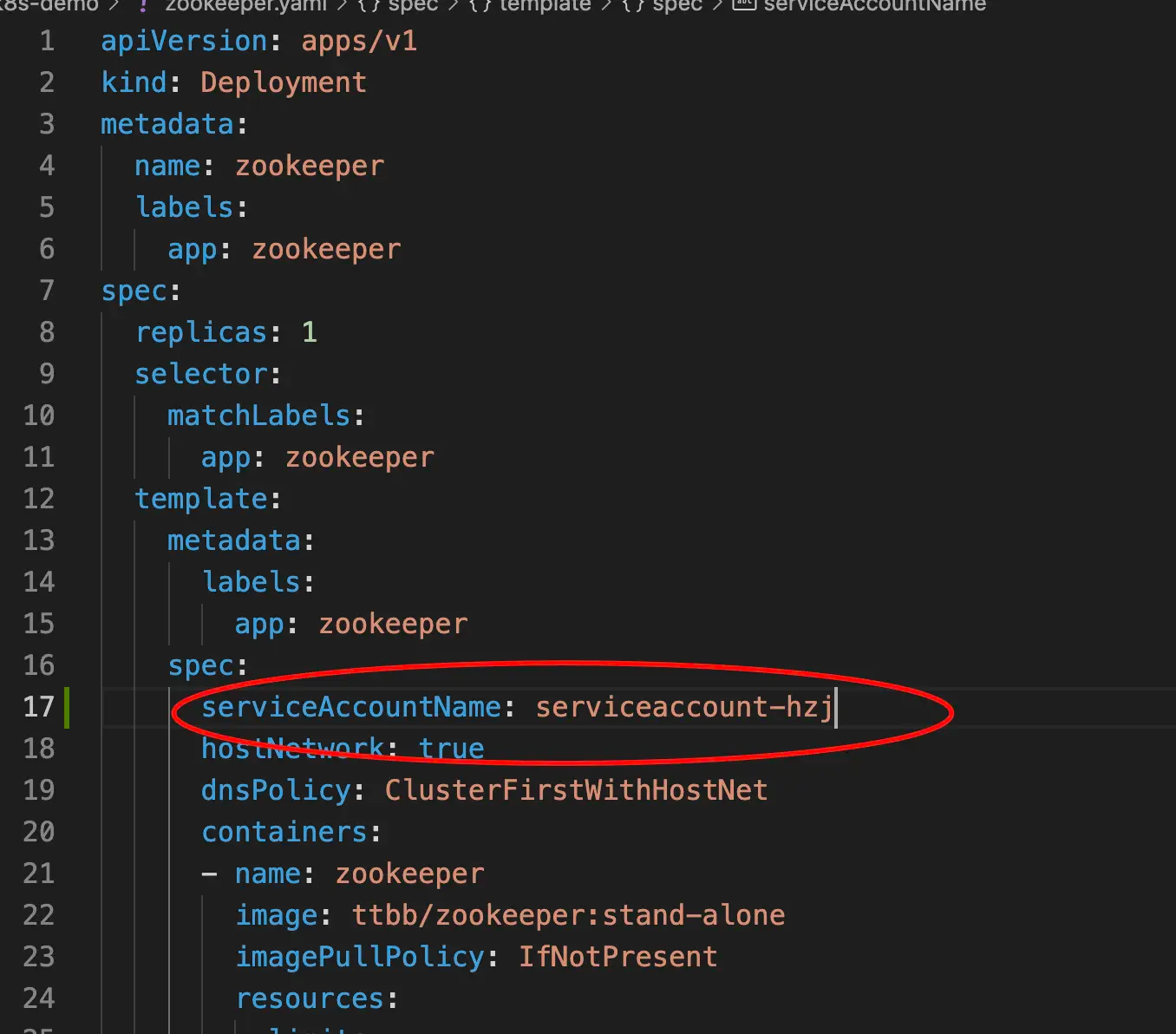
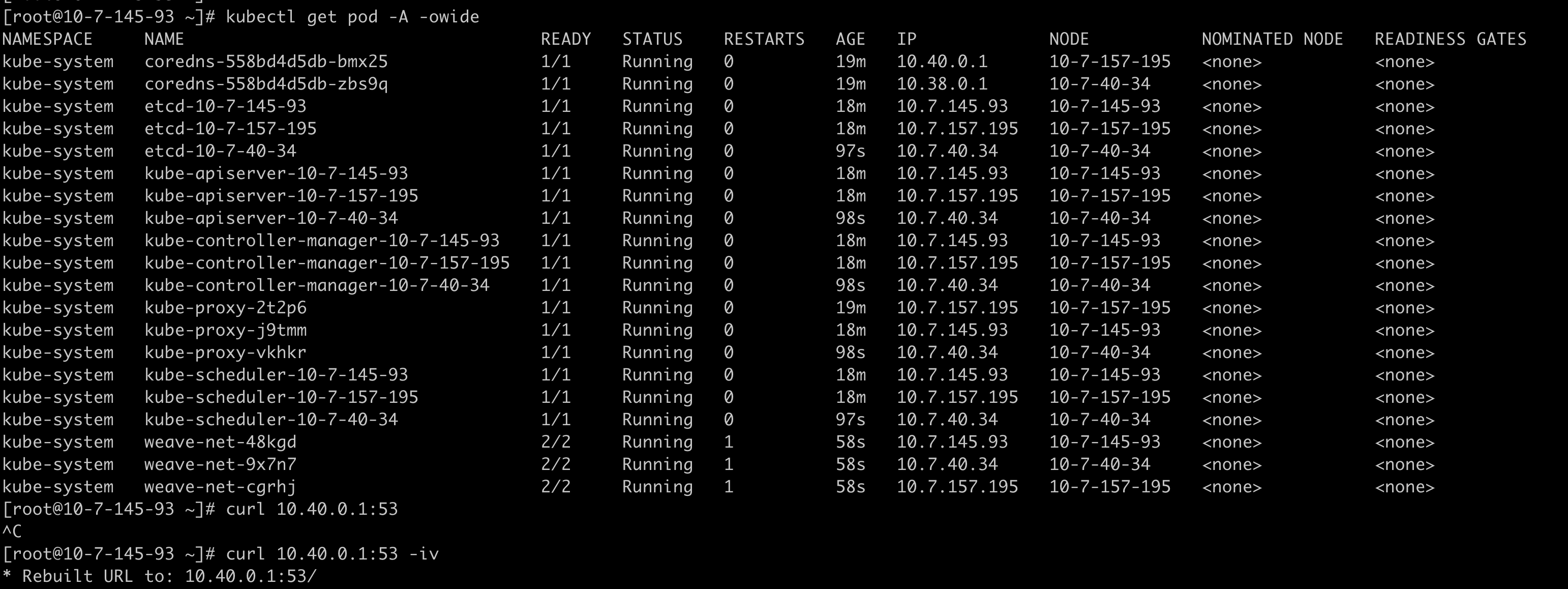
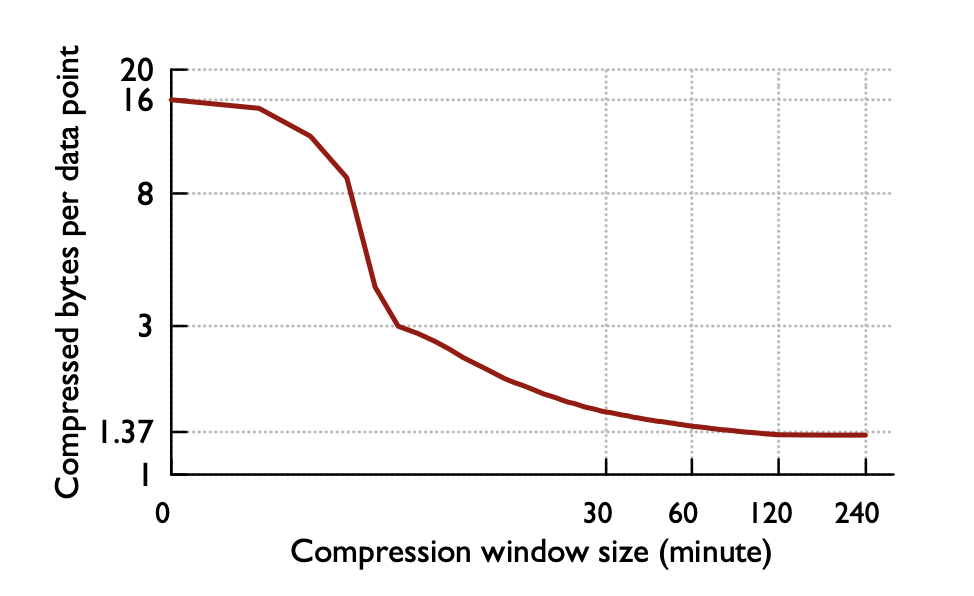
# Point to the internal API server hostname APISERVER=https://kubernetes.default.svc # Path to ServiceAccount token SERVICEACCOUNT=/var/run/secrets/kubernetes.io/serviceaccount # Read this Pod's namespace NAMESPACE=$(cat${SERVICEACCOUNT}/namespace) # Read the ServiceAccount bearer token TOKEN=$(cat${SERVICEACCOUNT}/token) # Reference the internal certificate authority (CA) CACERT=${SERVICEACCOUNT}/ca.crt # Explore the API with TOKEN curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api/v1/namespaces/default/pods
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
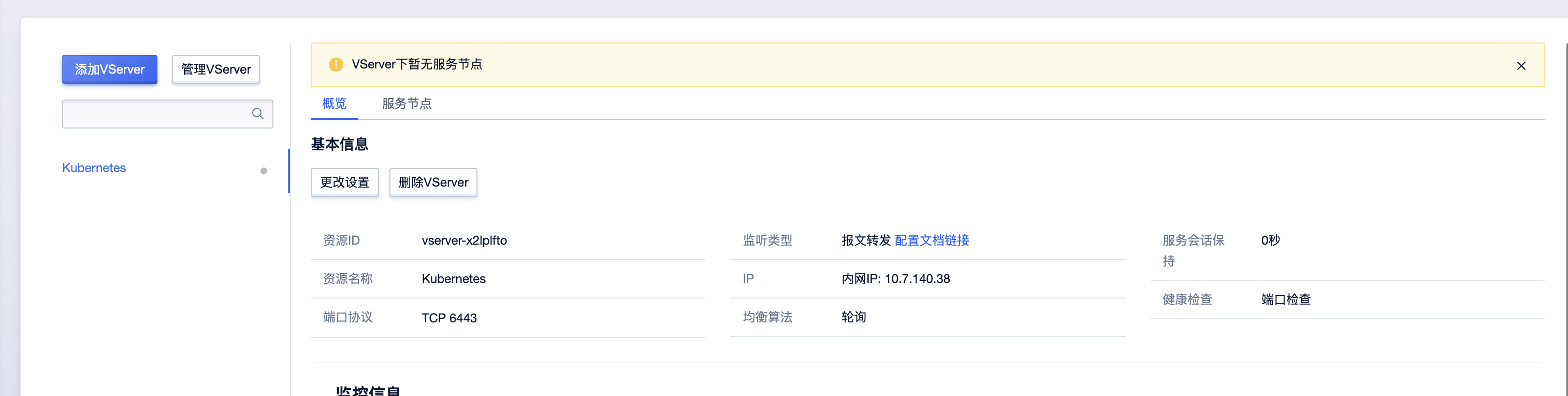
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
privatestatic String conv2Str(int value, int length) { if (length > 5) { thrownewIllegalArgumentException("length should be less than 5"); } Stringstr= String.valueOf(value); return AUX_ARRAY[length - str.length()] + str; }
--persistent -p [timeout] persistent service Specify that a virtual service is persistent. If this option is specified, multiple requests from a client are redirected to the same real server selected for the first request. Optionally, the timeout of persistent sessions may be specified given in seconds, otherwise the default of 300 seconds will be used. This option may be used in conjunction with protocols such as SSL or FTP where it is important that clients consistently connect with the same real server.
--set tcp tcpfin udp Change the timeout values used for IPVS connections. This command always takes 3 parameters, representing the timeout values (in seconds) for TCP sessions, TCP sessions after receiving a FIN packet, and UDP packets, respectively. A timeout value 0 means that the current timeout value of the corresponding entry is preserved.
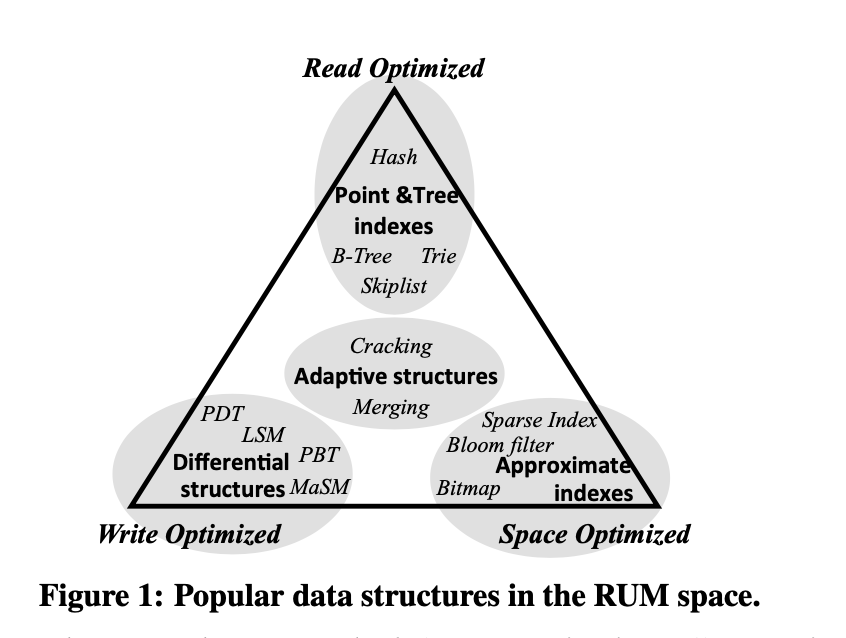
• Approximate (tree) indexing that supports updates with low read performance overhead, by absorbing them in updatable probabilistic data structures (like quotient filters).
• Morphingaccessmethods,combiningmultipleshapesatonce. Adding structure to data gradually with incoming queries, and building supporting index structures when further data reorganization becomes infeasible.
• Update-friendly bitmap indexes, where updates are absorbed using additional, highly compressible, bitvectors which are gradually merged.
• Accessmethodswithiterativelogsenhancedbyprobabilistic data structures that allows for more efficient reads and up- dates by avoiding accessing unnecessary data at the expense of additional space.