var buffer bytes.Buffer buffer.WriteString("\n") buffer.WriteString("# Entries added by HostAliases.\n") // for each IP, write all aliases onto single line in hosts file for _, hostAlias := range hostAliases { buffer.WriteString(fmt.Sprintf("%s\t%s\n", hostAlias.IP, strings.Join(hostAlias.Hostnames, "\t"))) } return buffer.Bytes() }
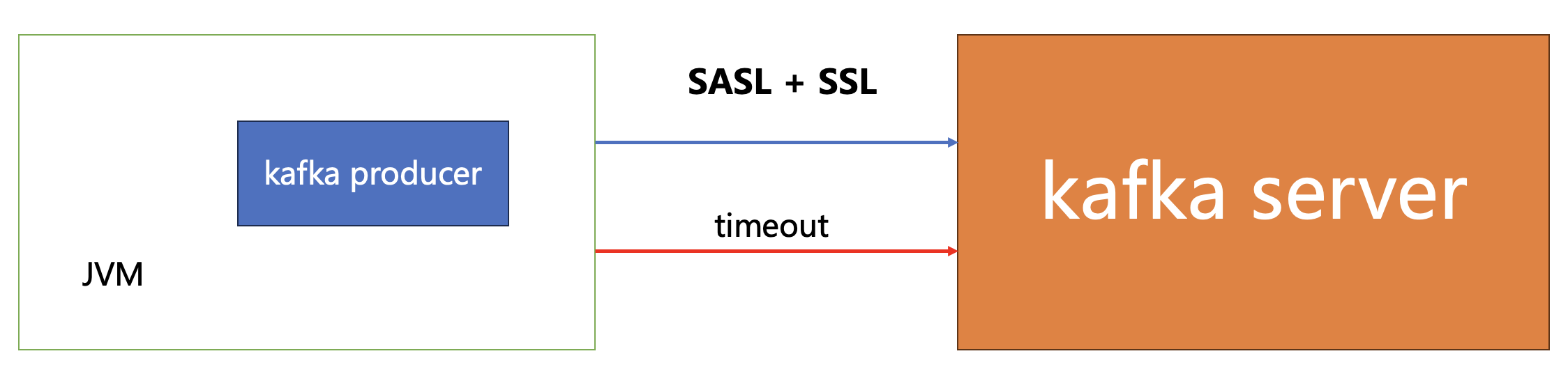
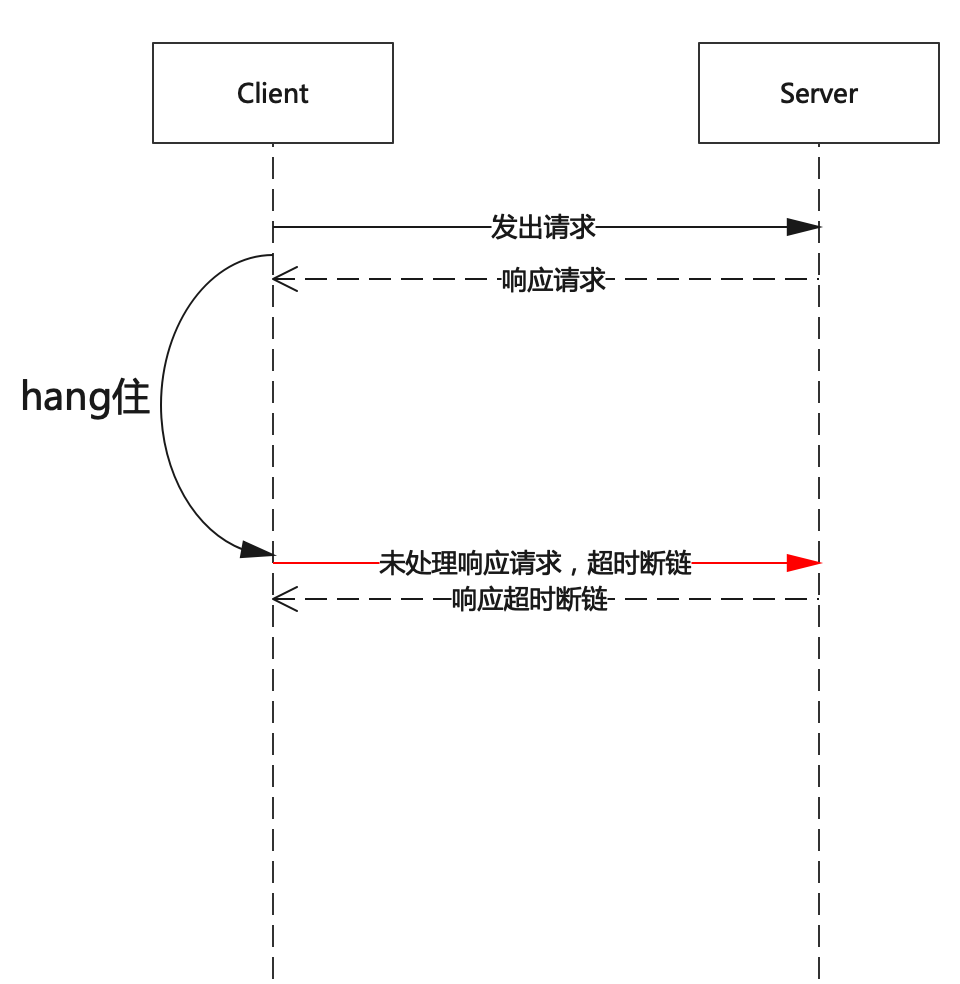
try { // 这里发出了请求 client.send(request, time.milliseconds()); while (client.active()) { List<ClientResponse> responses = client.poll(Long.MAX_VALUE, time.milliseconds()); for (ClientResponse response : responses) { if (response.requestHeader().correlationId() == request.correlationId()) { if (response.wasDisconnected()) { thrownewIOException("Connection to " + response.destination() + " was disconnected before the response was read"); } if (response.versionMismatch() != null) { throw response.versionMismatch(); } return response; } } } thrownewIOException("Client was shutdown before response was read"); } catch (DisconnectException e) { if (client.active()) throw e; else thrownewIOException("Client was shutdown before response was read");
@Override public List<ClientResponse> poll(long timeout, long now) { ensureActive();
if (!abortedSends.isEmpty()) { // If there are aborted sends because of unsupported version exceptions or disconnects, // handle them immediately without waiting for Selector#poll. List<ClientResponse> responses = newArrayList<>(); handleAbortedSends(responses); completeResponses(responses); return responses; }
"metrics-1@746" prio=5 tid=0xf nid=NA runnable java.lang.Thread.State: RUNNABLE at sun.management.ThreadImpl.getThreadInfo(Native Method) at sun.management.ThreadImpl.getThreadInfo(ThreadImpl.java:185) at sun.management.ThreadImpl.getThreadInfo(ThreadImpl.java:149)
bin/pulsar-admin namespaces | grep expiration get-subscription-expiration-time Get subscription expiration time for Usage: get-subscription-expiration-time [options] tenant/namespace set-subscription-expiration-time Set subscription expiration time for Usage: set-subscription-expiration-time [options] tenant/namespace Subscription expiration time in minutes remove-subscription-expiration-time Remove subscription expiration Usage: remove-subscription-expiration-time [options] tenant/namespace
sequenceDiagram
participant C as Client
participant B as Broker
loop
C ->> B: expire-messages-all-subscriptions Request
B -->> C: expire-messages-all-subscriptions Response
end
自定义代码实现Backlog大小策略
sequenceDiagram
participant C as Client
participant B as Broker
loop
C ->> B: stats-internal Request
B -->> C: stats-internal Response
alt messageBacklogSize < maxMessageBacklogSize
else messageBacklogSize >= maxMessageBacklogSize
Note over B,C: estimate the backlog position
C ->> B: get-message-by-id Request
B -->> C: get-message-by-id
Note over B,C: get the timestamp of the message
C ->> B: expire-messages-all-subscriptions Request
B -->> C: expire-messages-all-subscriptions Response
end
end