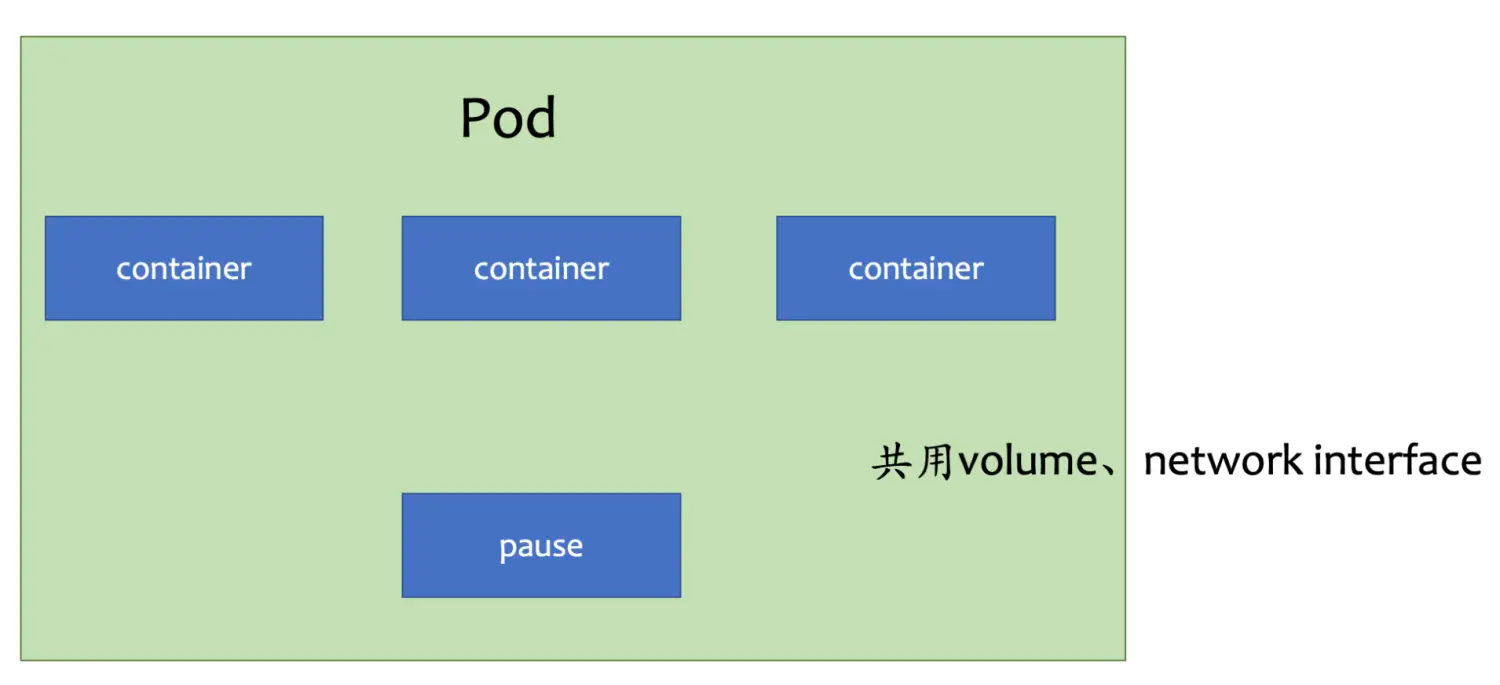
1
2
3
4
5
6
7
8
| HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:15:47 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:16:02 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:16:17 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:16:32 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:16:47 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:17:02 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:17:17 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
HttpResponse(200 OK,List(Server: akka-http/10.2.9, Date: Tue, 29 Mar 2022 00:17:32 GMT),HttpEntity.Strict(text/html; charset=UTF-8,31 bytes total),HttpProtocol(HTTP/1.1))
|