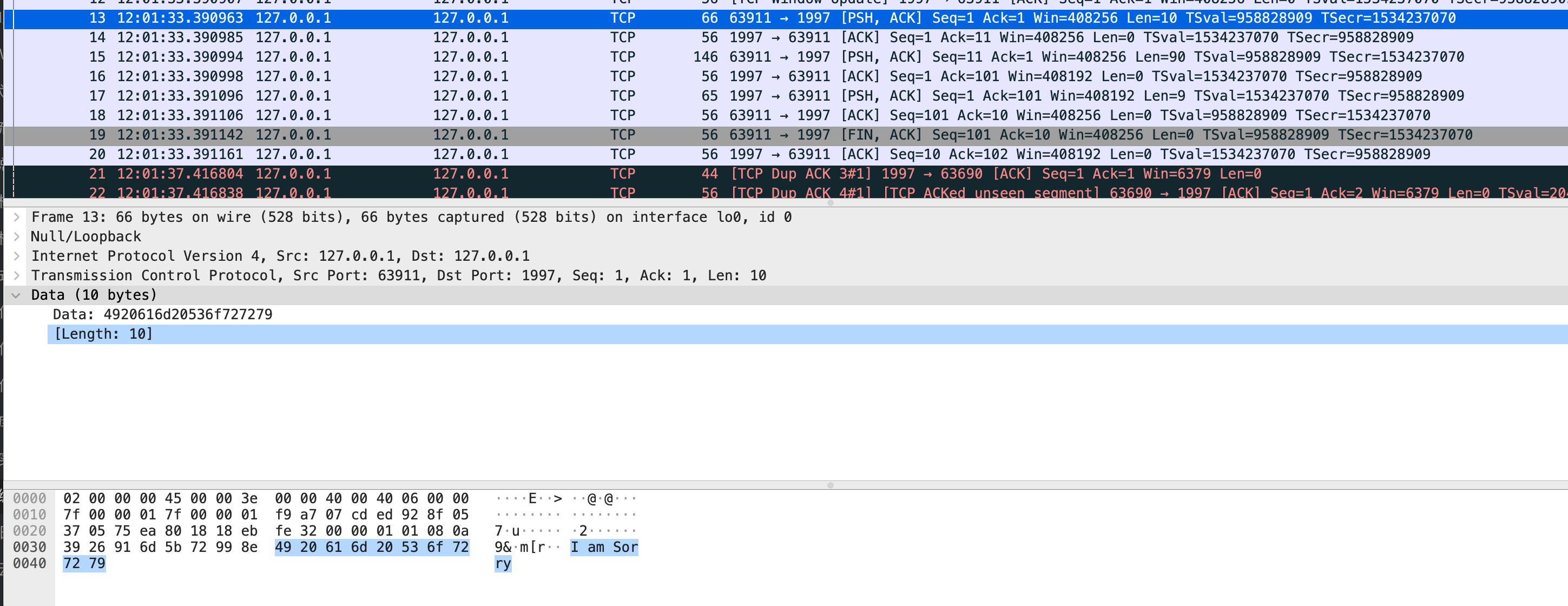
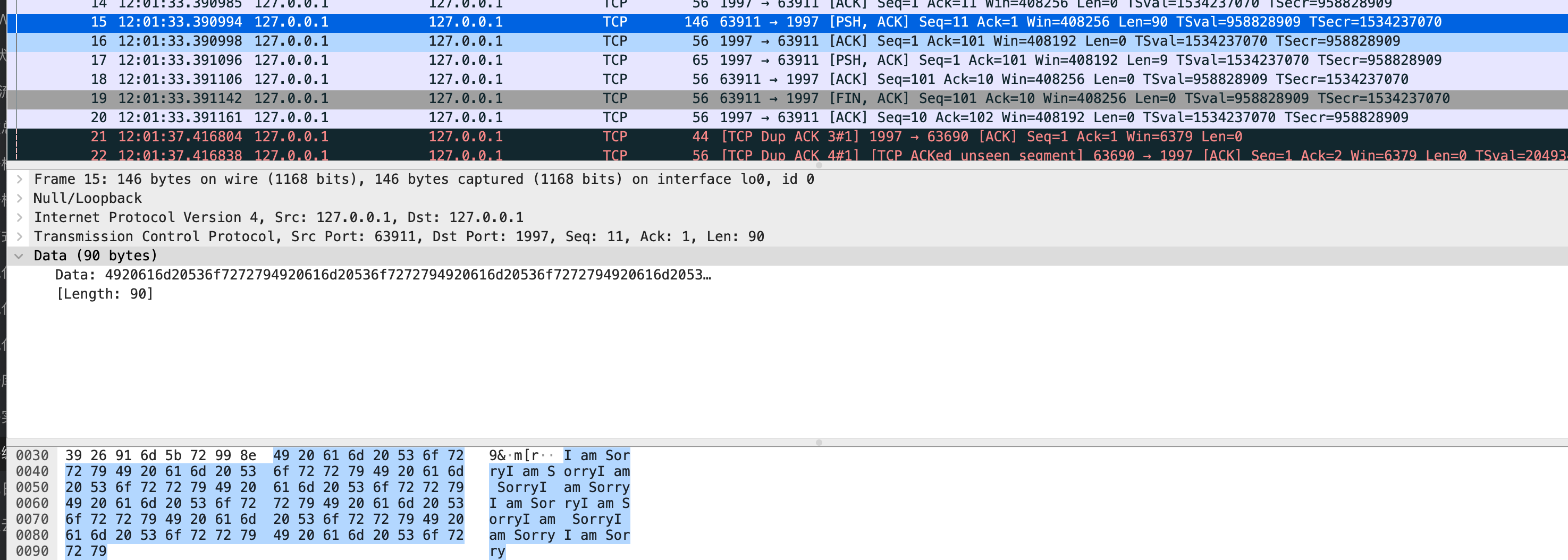
funcValueOf(i interface{}) Value { [...] return unpackEface(i) } // unpackEface converts the empty interface i to a Value. funcunpackEface(i interface{}) Value { e := (*emptyInterface)(unsafe.Pointer(&i)) [...] }
变量 e 现在包含有关该值的所有信息,例如类型或该值是否已导出。 反射还使用 unsafe 包通过直接在内存中更新值来修改反射变量的值。
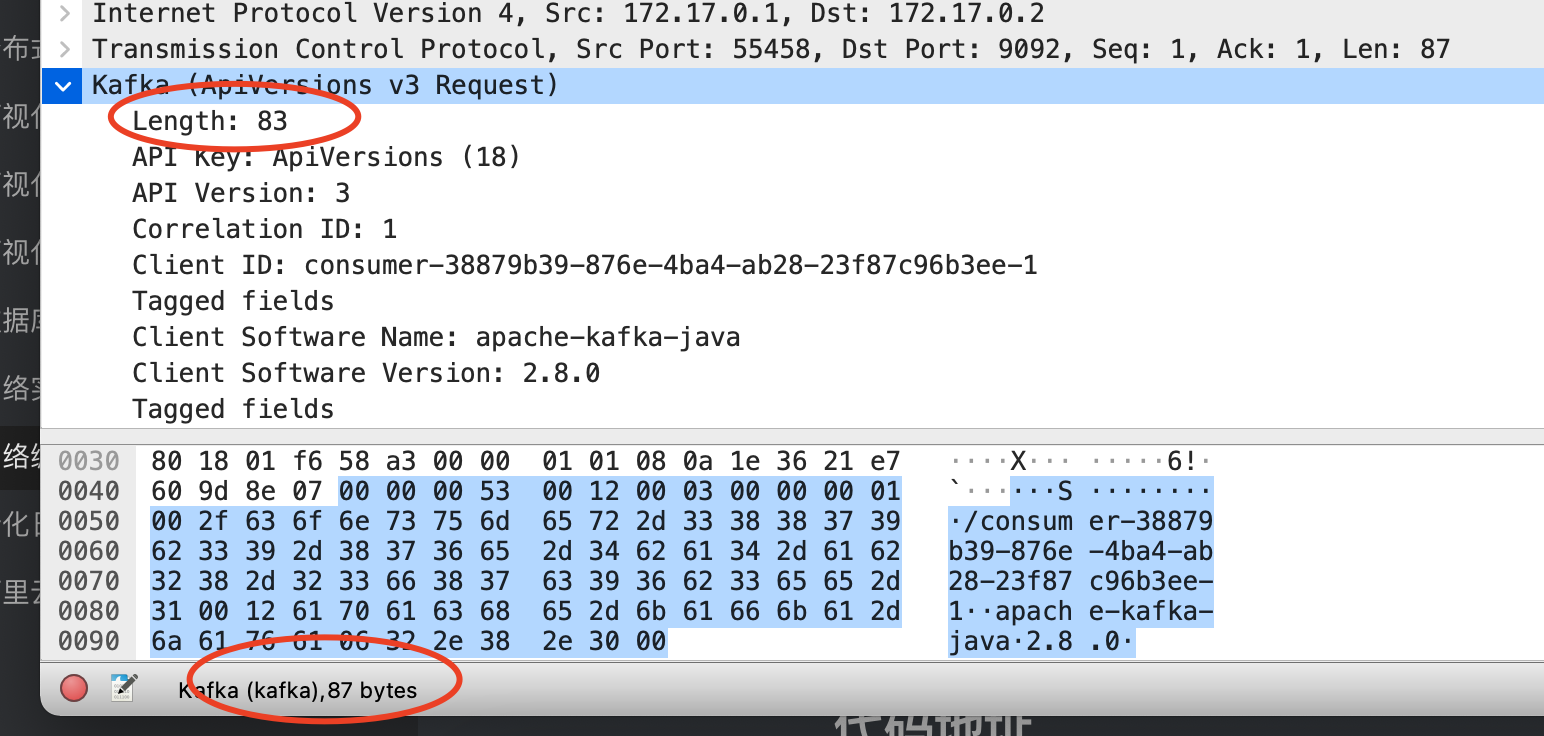
type clientConfig struct { // Number of worker goroutines publishing log events Workers int`config:"workers" validate:"min=1"` // Max number of events in a batch to send to a single client BatchSize int`config:"batch_size" validate:"min=1"` // Max number of retries for single batch of events RetryLimit int`config:"retry_limit"` // Schema WebSocket Schema Schema string`config:"schema"` // Addr WebSocket Addr Addr string`config:"addr"` // Path WebSocket Path Path string`config:"path"` // PingInterval WebSocket PingInterval PingInterval int`config:"ping_interval"` }
funcmain() { // src is the input that we want to tokenize. src, _ := ioutil.ReadFile(`main.go`)
// Initialize the scanner var s scanner.Scanner // positions are relative to fSet fSet := token.NewFileSet() file := fSet.AddFile("", fSet.Base(), len(src)) // nil means no error handler s.Init(file, src, nil, scanner.ScanComments)
// Repeated calls to Scan yield the token sequence found in the input for { pos, tok, lit := s.Scan() if tok == token.EOF { break } fmt.Printf("%s\t%s\t%q\n", fSet.Position(pos), tok, lit) } }
GOSSAFUNC=main go tool compile main.go && open ssa.html
SSA阶段
SSA优化解析
start Tab上生成了最开始的SSA
变量 a 和 b 与 if 条件一起在此处突出显示,以便我们稍后查看这些行是如何更改的。 代码还向我们展示了编译器如何管理 println 函数,它被分解为 4 个步骤:printlock、printint、printnl、printunlock。 编译器会自动为我们加锁,并根据参数的类型调用相关方法正确打印。 在我们的示例中,由于 a 和 b 在编译时已知,编译器可以计算最终结果并将变量标记为不再需要。 opt阶段 会优化这部分: